The Hype vs. The Test
NVIDIA calls the DGX Spark an "AI supercomputer." It costs $3,999. It's powered by the GB10 Grace Blackwell Superchip. On paper — 1 petaFLOP of AI performance, 128GB of unified memory, the full NVIDIA software stack pre-installed.

Sounds incredible. So I ran a real workload on it.
GPT-OSS 20B via Ollama. 50 concurrent requests. No synthetic benchmarks. A test that mirrors what we actually need for a client's AI call analysis pipeline processing 150K+ calls daily.
Here's what happened.
The Numbers
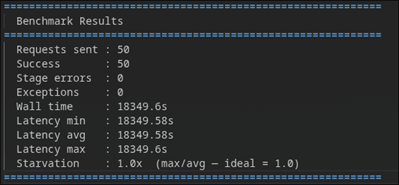
All 50 requests completed successfully. Zero errors. Zero crashes. Rock solid stability.
But:
- Wall time: 18,349.6 seconds (~5.1 hours)
- Average latency: ~18,350 seconds per request
- Power draw: ~40W peak
- Temperature: ~70°C max
The system processed all 50 requests sequentially. Over five hours for the full batch.
For comparison, an RTX 5090 decodes the same model at roughly 213 tokens/sec. The Spark manages about 50 tokens/sec. That's a 4x speed gap.
An RTX 5080 at ~155 tokens/sec would be 3x faster.
Even a used RTX 3090 from 2020 hits ~112 tokens/sec on models it can actually load.
If you stopped reading here, you'd think the DGX Spark is a terrible purchase. But that conclusion misses the entire point of this machine.
Why It's Slow: The Bandwidth Bottleneck
The DGX Spark isn't slow because it has a bad GPU. It has a Blackwell GPU with 5th-gen Tensor Cores — the same architecture powering NVIDIA's latest data center hardware.
It's slow because of memory bandwidth.
Token generation in large language models is memory-bound, not compute-bound. The speed at which you can generate tokens is directly tied to how fast you can feed model weights from memory to the GPU.
Here's the bandwidth comparison:
GPU Memory Bandwidth : RTX 3090 936 GB/s (dedicated GDDR6x) RTX 5080 960 GB/s (dedicated GDDR7) RTX 5090 ~1,500 GB/s (dedicated GDDR7) DGX Spark 273 GB/s (shared LPDDR5x)
The Spark's memory bandwidth is 3.5x lower than an RTX 5080. That's the bottleneck. Not the GPU, not the architecture, not the software. The data pipe is narrow.
NVIDIA chose LPDDR5x over HBM or GDDR7 for a reason — power efficiency and cost. The trade-off is bandwidth. And for inference throughput, that trade-off hurts.
What Nobody Mentions: The 5080 Can't Even Run This Test
Here's where the narrative flips.
I ran GPT-OSS 20B on the DGX Spark. The RTX 5080 cannot load this model.
16GB of VRAM. A 20B parameter model at full precision needs more memory than the card physically has. Even with aggressive Q4 quantization, you're pushing limits. Anything above ~13B on a 5080 is a fight against OOM errors.
The RTX 5090 with 32GB? It handles up to ~32B models. But try loading a 70B model and you're out of memory.
The DGX Spark with 128GB? It loads 200B parameter models locally. No quantization tricks. No memory gymnastics. Just loads it and runs.
Based on Q4 quantization. Full precision requires ~2x the VRAM.
That's the table that tells the real story. Speed means nothing if the model doesn't fit in memory.
The Full Head-to-Head
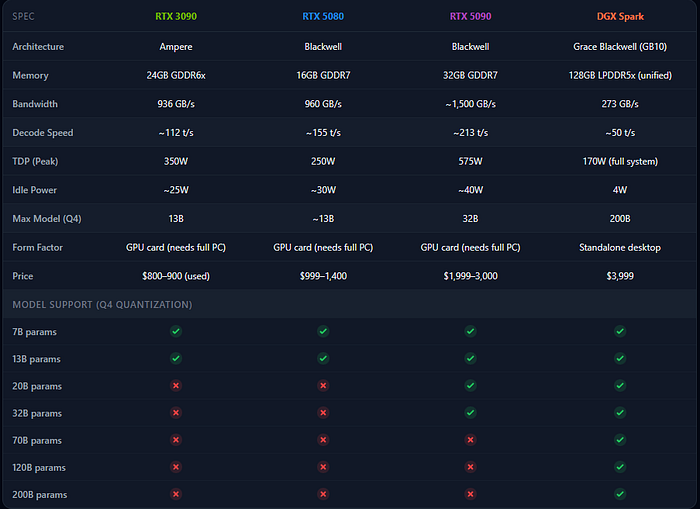
A few things jump out from this table:
The total system cost gap is smaller than it looks. The RTX 5090 is $2,000+ for just the GPU card. Add a motherboard, CPU, PSU (you need 850W+), case, and storage — you're looking at $3,500–4,500 for a complete build. The DGX Spark is $3,999 and it's a complete, ready-to-go system.
Power efficiency is absurd. The DGX Spark idles at 4 watts and peaks at 170W for the entire system. A full RTX 5090 build draws 700W+ under load. If you're running 24/7 inference, the electricity cost difference adds up fast.
The Spark is a standalone box. Plug it in, SSH in, start running models. No build. No driver headaches. No PSU compatibility concerns. NVIDIA's entire AI stack is pre-installed.
So Who Should Buy What?
After running these benchmarks, here's my honest breakdown:
Buy consumer GPUs (RTX 5080/5090) if:
- Your models fit within 16–32GB VRAM
- You need fast token generation for real-time or low-latency applications
- You're running 7B–32B models in production
- You're building a multi-purpose machine (gaming, rendering, AI)
- Budget matters more than model size
Buy the DGX Spark if:
- You need to run 70B–200B parameter models locally
- You're doing local fine-tuning (you're not fine-tuning 70B on 16GB VRAM)
- Data privacy requires everything to stay on your hardware — no cloud, no API calls
- Power efficiency and form factor matter (edge deployment, on-site installations)
- You want NVIDIA's full stack without building and maintaining a rig
- You're an AI agency or consultancy and need a flexible development platform that can handle any model size a client throws at you
Buy neither if:
- You need production inference at scale — get cloud GPUs or proper server hardware
- Your workload is light enough that API costs are under $100/month — the math doesn't justify hardware
What I Got Wrong in My First Post
A week ago, I posted about unboxing the DGX Spark. I was excited about the 4W idle power draw and the 128GB memory. I said I was curious about real-world performance.
Now I have real numbers, and here's what I'd tell myself:
Temper expectations on inference speed. The marketing says "AI supercomputer." The bandwidth says "workstation." If you buy this expecting RTX 5090 speeds, you'll be disappointed.
The value is in capacity, not speed. The Spark doesn't compete on tokens per second. It competes on "can you even run this model?" For most consumer GPUs, the answer to 70B+ is no. For the Spark, it's always yes.
4W idle is genuinely game-changing for always-on deployments. If you need a box sitting on-site at a client location, running inference on demand, the power draw makes this practical in ways a 700W gaming PC build never could be.
What's Next
We're continuing to push this machine on our client's call analysis pipeline. Next round of tests:
- Token throughput across model sizes: 7B, 13B, 20B, 70B quantized
- Power consumption under sustained 24-hour load
- Head-to-head cost analysis: DGX Spark vs. monthly cloud API costs for our specific workload
- Testing whether the sequential request handling is an Ollama limitation or a hardware one
No hype. Just numbers. Follow along if you want the unfiltered results.
Mubashir Rahim is the founder of Dojo Labs, an AI automation agency building AI solutions for US mid-market clients.
Tags: Artificial Intelligence, NVIDIA, Machine Learning, Edge Computing, AI Infrastructure