YOLO models are powerful object detection models. Accuracy values are competitive, and FPS values are amazing for real-time applications, but object detection is not all about YOLO. There are several different model architectures, and they all have different pros and cons.
- Single-Stage Detectors: YOLO, SSD
- Two-Stage Detectors: Fast R-CNN, Faster R-CNN
- Transformer-Based Detectors: DETR
In this article, I will talk about these architectures and show you how to train and run these models.

Now, I will explain each of the three architectures and give you general instructions for training and running models with custom datasets. I already have step-by-step guides for training these models on my personal website; I will share the links in advance.
Now, lets start with single-stage detectors.
1. Single-stage Detectors: YOLO, SSD
Unarguably, the most popular object detection model out there is YOLO, and the most powerful thing about YOLO is its speed. But have you ever thought about why YOLO is fast?
The answer is simple: because of its architecture. YOLO is a single-stage detector, meaning that everything is done on a single neural network. With a single pass, bounding box and label information are generated.
The CNN backbone extracts features and generates feature maps, and the detection head makes all the predictions.
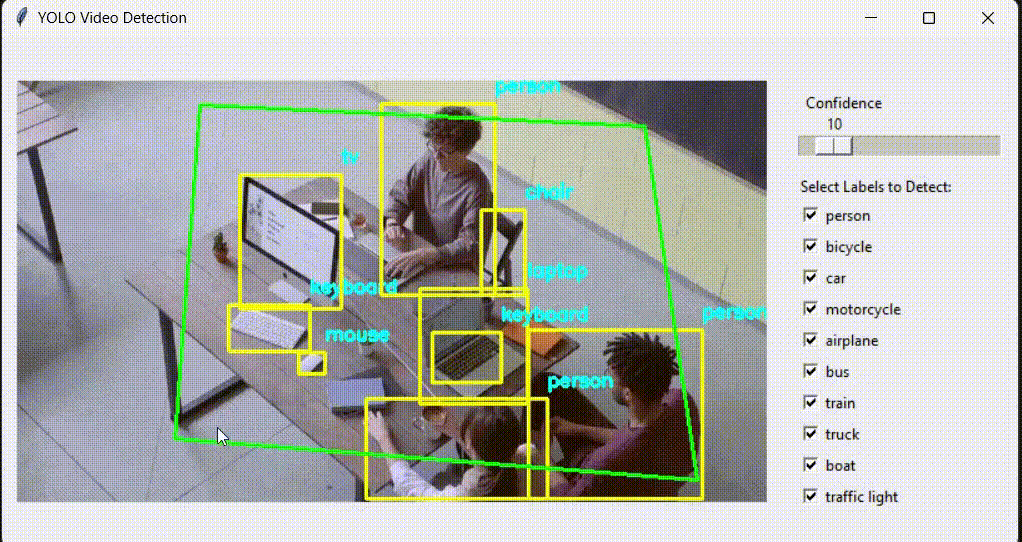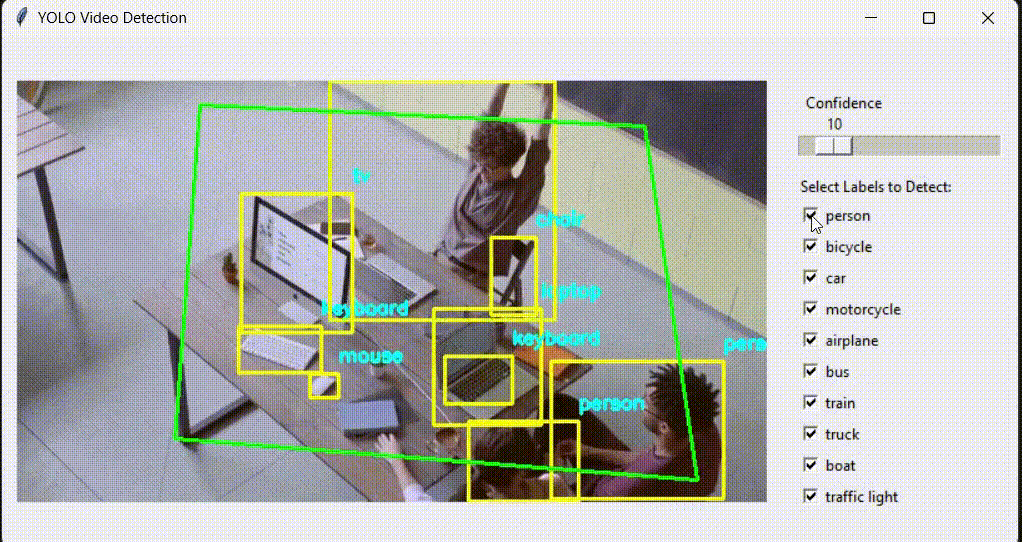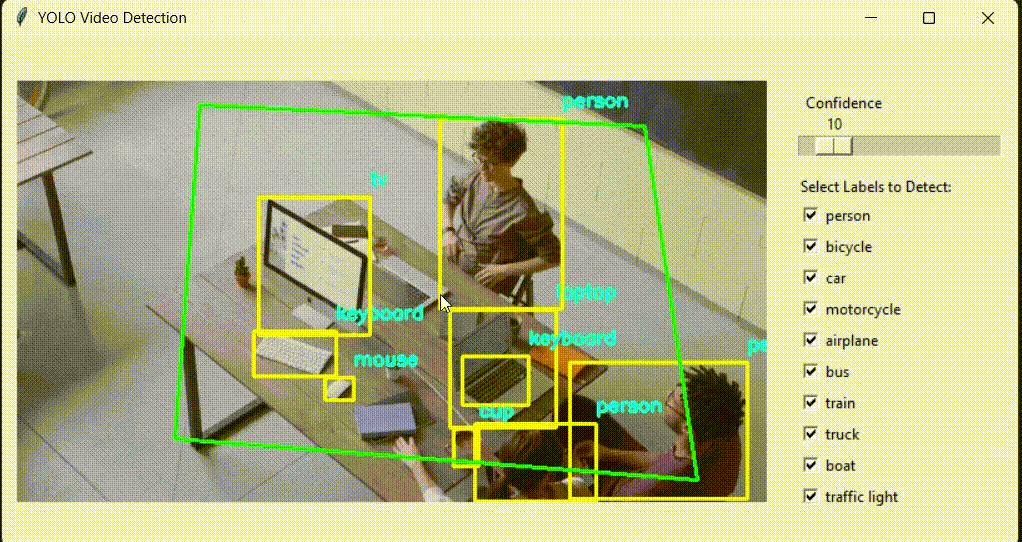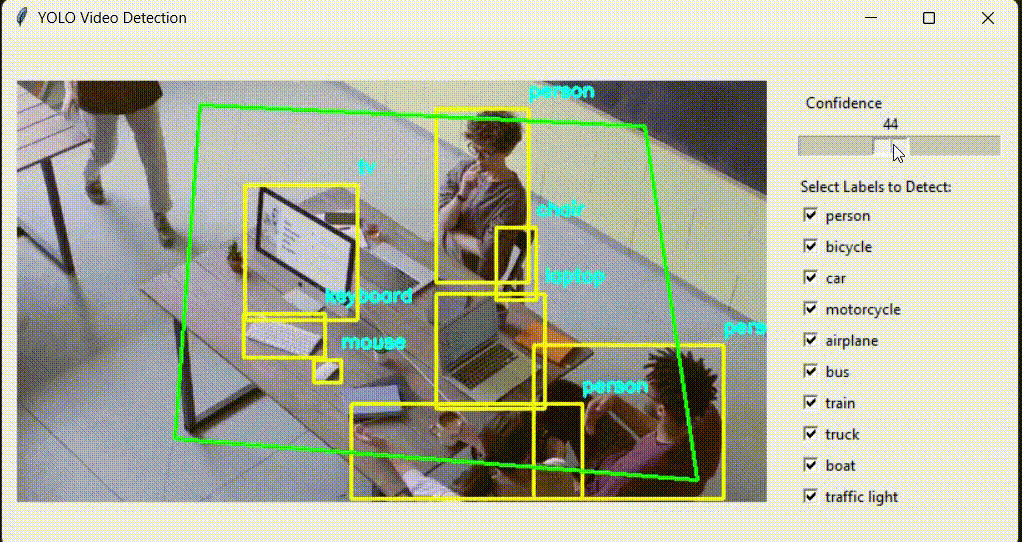
Are YOLO models popular only because they are fast? Of course not. I think there is one big advantage of YOLO, and that is Ultralytics. Thanks to Ultralytics, training a YOLO model is way easier than other models. You only need to choose a dataset from the internet (Kaggle, Roboflow, GitHub), install Ultralytics, then train a model. With less than 50 lines, you can train a YOLO model on a custom dataset. I already have an article about it; even with zero knowledge, you can follow it and train a YOLO model on a custom dataset.
There are other single-stage detectors such as SSD. It detects objects from multi-scale feature maps. In simpler terms, detection is done on both high- and low-resolution feature maps. SSD is a little bit outdated object detection model. There are different SSD models:
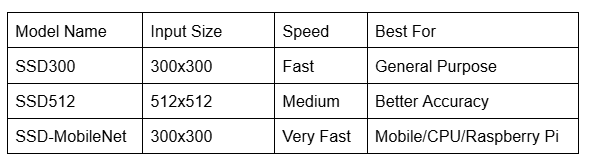
I don't have an article about training an SSD object detection model, but you can find some resources on the internet. It is possible using PyTorch.
2. Two Stage Detectors: Faster R-CNN
As the name suggests, there are two different stages. In the first stage, regions that are likely to contain objects are detected, and it is called region proposal. In the second stage, objects are detected from these proposed regions.
Because there are two stages, two-stage detectors are not applicable for real-time applications. But there is one important advantage, and that is the detection of small objects.

The CNN backbone extracts features, and FPN (Feature Pyramid Network) generates feature maps from different scales. Detection is done on both small and bigger feature maps (width × height), and small objects can be detected more efficiently from bigger feature maps.
I already have an article about how to train Faster R-CNN object detection models on any dataset; you can read it. From installation to dataset preparation, everything is ready for you.
3. Transformer Based Detectors: DETR
Both single- and two-stage detectors have a lot in common in general. Transformer-based detectors are different from these two. Now, transformers are the key points. When I say transformer, it is not Bumblebee :)
There are still CNN backbones for feature extraction. In addition to the CNN backbones, there are additional encoders and decoders. In simpler terms, the encoder learns about the global image (relation between different patches of the image, self-attention layer) from these features, and the decoder transforms the learned features to make predictions, which are class and bounding box predictions.
By the way, DETR stands for DEtection TRansformer. Again, you can find an extensive tutorial about how to train DETR object detection models on any dataset on my personal website about computer vision (visionbrick.com).