I remember two of my PhD colleagues at the University of Copenhagen struggling for almost two months while training a simple autoencoder on a large dataset (50,000 MRI scans). In their words: "We changed one parameter, and an entire week of training became useless. It was a nightmare."
During that same summer, I attended a summer school at UCPH on Self-Supervised Learning (SSL). Every speaker praised how powerful SSL is, but by the end they all admitted how fragile it can be during training. After the summer school, I was clear about two things:
- I would definitely use SSL backbones (DINOv2, DINOv3, SAM encoder) in my projects and I did :).
- But I would never attempt to train an SSL model from scratch if an equally good alternative already exists especially since a PhD in Denmark lasts only three years (and I was in third year :) ).
If you can't read the article further please click here

Yesterday, while scrolling, I came across an article about a new paper (LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics) and immediately got excited to read it and write about it. This paper is written by two amazing scientists Yann LeCun and Randall Balestriero, and it might actually fix the long-standing mess in self-supervised learning. LeJEPA is their attempt to bring simplicity and theoretical clarity to pretraining, stripping away the fragile heuristics we've all been forced to rely on. After spending a few days with the paper and the code, I 'm cautiously optimistic that this could mark a real shift in how we approach training custom models.The Problem Nobody Talks About
Here's what self-supervised learning actually looks like in 2025: you're not just training a model to learn good representations. You're also fighting against something called "representational collapse," where your model decides the easiest way to solve your objective is to map every image to basically the same vector. Game over.
To prevent this disaster, researchers have accumulated a zoo of tricks over the years. Most modern SSL methods use some combination of:
- Stop-gradients to prevent certain paths from updating
- Teacher-student architectures with exponential moving averages
- Additional predictor networks sitting on top of encoders
- Carefully designed data augmentations
- Extra "register tokens" in transformers
- Elaborate learning rate schedulers
- Batch sizes that would make your AWS bill cry
None of these tricks are there because they improve performance directly. They're defensive programming against collapse. And every time you want to train on a new domain, architecture, or scale, you're back to square one tuning all these knobs.
LeJEPA's proposition is simple but radical: what if we could design an objective that's stable by construction, so we don't need any of this?
The Core Insight
The heart of the paper is actually quite elegant. The authors prove mathematically that for JEPAs (Joint-Embedding Predictive Architectures), the optimal embedding distribution (the one that minimizes your risk on downstream tasks) is an isotropic Gaussian. Picture a nice, symmetric cloud of points in high-dimensional space, spread out evenly in all directions with equal variance.
Once you know what your embeddings should look like, the training objective becomes straightforward:
- JEPA prediction loss: Make different views of the same image agree in representation space (standard stuff)
- SIGReg: Gently push your embedding distribution to look like that ideal Gaussian
That's it. One trade-off parameter λ between these two objectives. No teacher networks, no stop-gradients, no predictor heads, no exotic schedulers.
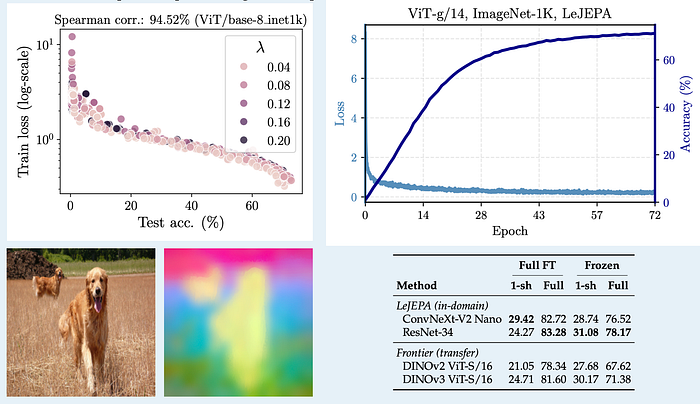
SIGReg: The Clever Bit
The innovation here is SIGReg (Sketched Isotropic Gaussian Regularization). Instead of trying to directly enforce that your high-dimensional embeddings follow a Gaussian distribution (which is statistically nasty), they use a clever workaround:
- Take many random 1-D projections of your embedding vectors
- For each projection, run a statistical test to see if it looks like a standard normal distribution
- If your projections don't look Gaussian, backprop through that signal
The beauty is that this approach is computationally cheap: linear in both batch size and number of projections. The implementation really is around 50 lines of code. And because it's catching collapse through statistical tests on projections rather than architectural hacks, it's much more robust.
If your model starts collapsing everything to a point, those projected distributions will fail the Gaussian test spectacularly, and SIGReg pushes back. You get well-spread embeddings without needing the usual scaffolding.
What This Means in Practice
The paper demonstrates something I found genuinely surprising: LeJEPA works across 60+ architectures (ResNets, ConvNeXts, ViTs, MaxViTs, Swin Transformers) and 10+ datasets, scaling up to 1.8 billion parameters, with essentially the same recipe. No architecture-specific tuning. No per-dataset hyperparameter search.
On ImageNet-1k with a ViT-H/14, LeJEPA hits around 79% top-1 accuracy on linear evaluation. That's competitive with state-of-the-art methods that require far more babysitting.
But here's what really caught my attention: the training loss actually correlates with downstream performance. The paper shows Spearman correlations up to 0.99 between the SSL loss curve and eventual linear probe accuracy. This might not sound exciting, but think about what it means: you can do model selection and early stopping just by watching your training loss. No need to burn GPU hours running linear probes on every checkpoint.

For practitioners, this is huge. Instead of training multiple models and probing them all, you can essentially read downstream performance off your loss curve.
The In-Domain Story
Here's where things get really interesting for anyone not working at a FAANG lab with unlimited compute. The default playbook today is: "Take a DINOv2 backbone pretrained on millions of images and hope it transfers to your domain."
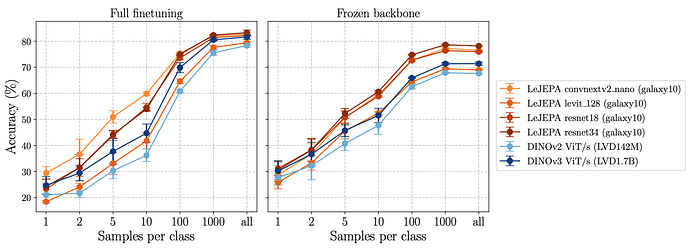
LeJEPA suggests a different path. When the authors pretrained directly on domain-specific datasets like Galaxy10 (astronomy) or Food-101, domain-specific pretraining beat transfer learning from massive generic models. A relatively small LeJEPA model trained on galaxy images outperformed a huge DINOv2 model pretrained on natural images.
This is a potential paradigm shift. You might not need to crawl the entire internet or match someone's ViT-G trained on hundreds of millions of images. With a clean, stable objective like LeJEPA, focused in-domain pretraining on your specific data becomes viable again.
For specialized applications (medical imaging, industrial inspection, satellite imagery, or any niche domain) this opens up new possibilities. You can train representations shaped by your actual data distribution, not ImageNet dogs and cats.
How I'd Actually Use This
If I were starting a project with unlabeled domain data tomorrow, here's my mental workflow:
1. Pick any backbone you like LeJEPA is architecture-agnostic. ResNet, ConvNeXt, ViT: doesn't matter. Use what you know works for your task.
2. Pretrain with LeJEPA on your unlabeled pool Use their multi-crop augmentation recipe (2 global + 6 local views). Start with their default hyperparameters. Don't overthink it.
3. Monitor the training loss That's basically it. Maybe track k-NN accuracy on a small validation set if you have labels, but the loss curve should tell you most of what you need to know.
4. Freeze and evaluate After pretraining, freeze the backbone and train a small task-specific head on your labeled data. Compare against your current baseline (probably ImageNet or DINOv2 transfer).
5. Own your backbone No dependency on someone else's model zoo. No licensing concerns. Just your data, your SSL objective, and a clean ~50-line regularization term.
What This Isn't
Let me set expectations: LeJEPA isn't going to magically beat every SSL method on every benchmark. That's not the point. The value proposition is: competitive performance without the fragility.
The current work focuses on vision. If you're working with text-image pairs, video, or speech, you'll need to adapt things. And you still need decent compute for large-scale pretraining (training a ViT-g isn't free).
But as a design philosophy, it's refreshing:
- Prove theoretically what your embeddings should look like
- Build an objective that enforces exactly that
- Remove the heuristics
- Get a loss that actually tells you about downstream performance
Why This Matters Now
We're seeing a pattern across recent AI research: Kimi Linear attacking the KV cache problem, Kimi K2 exploring reasoning depth, and now LeJEPA going after the most annoying part of SSL training (all that hacky stability machinery).
All three share a philosophy: fewer knobs, cleaner math, better scalability, and systems that humans with finite time and patience can actually implement.
My prediction: over the next year, we'll see LeJEPA-style objectives quietly replace a lot of the fragile SSL setups in both research codebases and production systems. It's not as flashy as "1 million token context" or "GPT-5," but for anyone who actually trains custom encoders on real data, this is the kind of improvement you feel every day.
The era of spending your weekends debugging why your self-supervised training collapsed might finally be ending. And honestly? It's about time.
I'll write another tutorial article on LeJEPA. I'm getting some errors at the moment, but as soon as I fix them, I'll publish it.
See you soon :)
Resources: