
How does AI generate images based on a prompt or reference image?
Most AI image generators are based on diffusion models: DALL-E 3, MidJourney, Stable Diffusion 3, Imagen 2, FLUX.1, etc.
Since diffusion models are inspired by statistical physics, and they use Markov chains to slowly transform one distribution into another, most diffusion papers and articles contain a lot of math [1].
So, this article tries to explain diffusion models in a technical way without relying on complicated math.
Diffusion Models
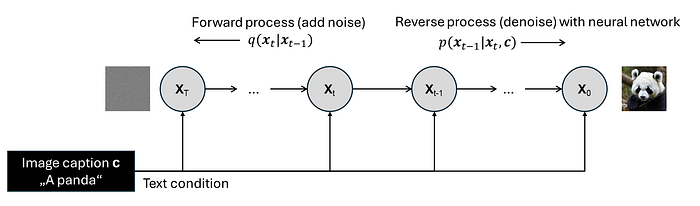
A diffusion model has two processes: a forward process and a reverse process. Both processes perform T steps of diffusion (usually T=1000).

In the forward diffusion process q (right to left), we start at time step t=0 with an input image x0. At each step, we add some noise to the previous image xt-1 to get a new image xt. More specifically, we add noise from a multivariate Gaussian distribution that is defined by a set of chosen hyperparameters.
The interesting part is the reverse process p. The key idea is to train a deep neural network (with learnable parameters theta) on a large image dataset to iteratively reverse the forward process.
In the reverse process, we start at time step t=T with a completely noisy image xT and we want to end up with a denoised image x0. At each step, the neural network predicts what Gaussian noise should be added to the previous image xt to produce the next image xt-1.
More specifically, at each time step, the neural network estimates the mean and variance of the noise for each pixel of our image [1]. The variance is often fixed to known constants (hyperparameters), so only the mean needs to be predicted [2].

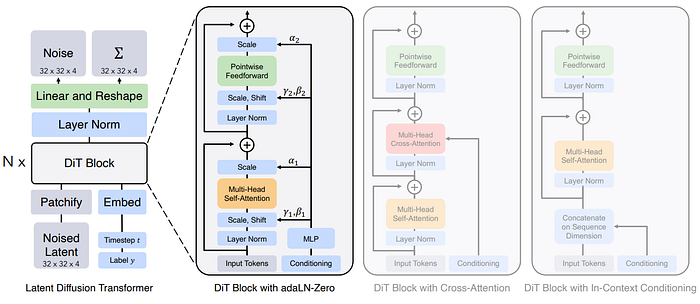
Originally, Stable Diffusion used the Convolutional Neural Network (CNN) U-Net as a model architecture, but now Transformer-based architectures such as the Diffusion Transformer (DiT) or the MultiModal Diffusion Transformer (MMDiT) are being used to generate images [3, 4].
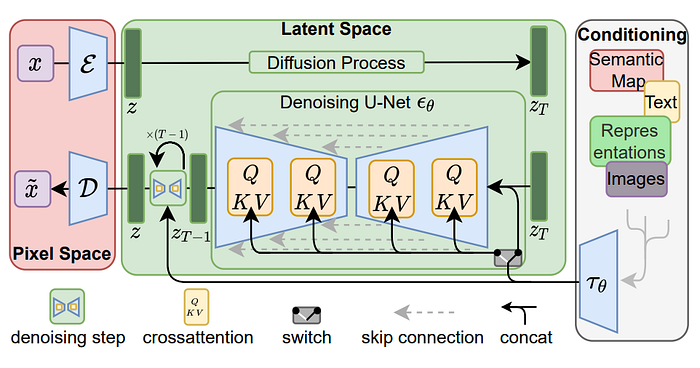
It is possible to work directly with images x in pixel space. However, it is more efficient to transform an image into a smaller latent space with an encoder, perform the diffusion process there, and then transform it back into an image with a decoder. These models are called Latent Diffusion Models (LDMs) [5].
To achieve high resolution images, multiple diffusion models can be stacked. For example, in DALL-E 2, the first diffusion model generates a low resolution 64 x 64 pixel image. Then a diffusion upsampler model transforms this image into a 256 x 256 image, and a second upsampler model transforms it into a 1024 x 1024 image [6].
The diffusion model as described above can generate random images similar to the images in the training data. However, we are missing one crucial thing: the prompt that tells the model what to generate.
Guided Diffusion
Guided diffusion means moving from the basic unconditional diffusion model to a conditional diffusion model. In guided diffusion, we use additional information, such as a caption c or a class label y, to guide the diffusion process in a desired direction.
Classifier guidance uses a classification model is used to predict a class label y given the current image xt during the reverse diffusion process.
CLIP guidance uses the pre-trained CLIP model as the classification model, which compares an encoded image f(xt) to an encoded text caption g(c) using the dot product to see how similar the image and caption are [7].
This information is used to modify the Gaussian noise predicted by our neural network, thus guiding the image in a desired direction at each time step t. The amount of steering can be controlled by a parameter called gradient scale or guidance scales. A scale of s=0 completely ignores the guidance and the larger the value of s, the more guidance is given to the model [8].
Another option is to transform the conditional guidance information and then pass it to the neural network architecture, for example by concatenating image caption embeddings to the tokens inside a Transformer-based DiT [3].
Either way, the text prompt / image caption is transformed and then injected into the conditional diffusion models in some shape or form to provide guidance.
It is also possible to use images as input to a conditional diffusion model for guidance, for example, to provide a style reference.
Summary
Modern AI image generators use diffusion models at their core.
A diffusion model has a forward process that iteratively adds Gaussian noise to an image, and a reverse process where a neural network predicts Gaussian noise to reverse the forward process. The neural network is trained to do that on large image datasets.
A conditional diffusion model integrates additional guidance information, such as a text prompt, into the reverse process so that we can control what kind of images to generate. A parameter called guidance scale controls the amount of guidance.
References
[1] J. Sohl-Dickstein et al.: Deep Unsupervised Learning using Nonequilibrium Thermodynamics (2015), ICML
[2] J. Ho, A. Jain, and P. Abbeel: Denoising Diffusion Probabilistic Models (2020), NeurIPS
[3] W. Peebles, and Saining Xie: Scalable Diffusion Models with Transformers (2023), ICCV
[4] P. Esser et al.: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (2024), PMLR
[5] R. Rombach et al.: High-Resolution Image Synthesis with Latent Diffusion Models (2022), CVPR
[6] A. Ramesh et al.: Hierarchical Text-Conditional Image Generation with CLIP Latents (2022), arXiv preprint
[7] A. Nichol et al.: GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (2022), PMLR
[8] P. Dhariwal, and A. Nichol: Diffusion Models Beat GANs on Image Synthesis (2021), NeurIPS