It's so small you could run it on a potato. Okay, maybe not a literal potato, but it only needs around 0.5 GB of RAM. That's… basically nothing.
And of course, I couldn't resist trying to fine-tune it on something fun. So I picked chess.
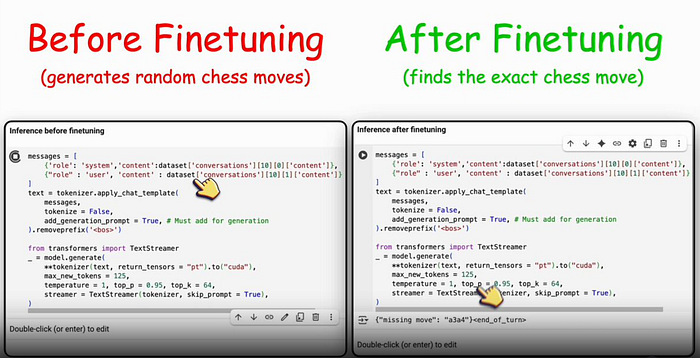
My goal: give it a nearly finished chess game, ask "what's the missing move?", and see if it could nail the answer.
All offline. No GPUs in the cloud. No credit card bills that make me cry.
What I Used
Here's my little toolkit for this experiment:
- Unsloth AI — makes fine-tuning small models ridiculously fast.
- Hugging Face Transformers — because it's the standard for running LLMs locally.
- ChessInstruct dataset — games with one missing move for training.
Step 1: Load the Model
This part's easy. Pull Gemma 3 in with Unsloth:
# pip install unsloth
from unsloth import FastLanguageModel
import torch
MODEL = "unsloth/gemma-3-270m-it"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = MODEL,
max_seq_length = 2048,
dtype = None,
load_in_4bit = False,
full_finetuning = False
)Boom. Model loaded.
Step 2: LoRA Fine-Tuning (a.k.a. Tiny Edits, Big Impact)
Instead of retraining the whole model (which would melt my laptop), I used LoRA. Think of it like giving the AI a few new neurons without replacing its whole brain.
from unsloth import FastModel
model = FastModel.get_peft_model(
model,
r = 128,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
use_gradient_checkpointing = "unsloth",
lora_alpha = 128,
lora_dropout = 0,
bias = "none",
random_state = 3407
)Step 3: Grab the Dataset
This dataset has incomplete chess games. Your job (or in our case, the AI's job) is to fill in the missing move.
from datasets import load_dataset
dataset = load_dataset("Thytu/ChessInstruct", split="train[:10000]")
print(dataset[0])Sample entry:
Moves: c2c4, g8f6, b1c3, …, ?, result: 1/2-1/2
Expected: e6f7Step 4: Make the Data Chat-Friendly
Models like to "talk" in a structured way, so I wrapped the data in a conversation format.
from unsloth.chat_templates import standardize_data_formats
dataset = standardize_data_formats(dataset)
def convert_to_chatml(example):
return {
"conversations": [
{"role": "system", "content": example["task"]},
{"role": "user", "content": str(example["input"])},
{"role": "assistant", "content": example["expected_output"]}
]
}
dataset = dataset.map(convert_to_chatml)Step 5: Training Setup
A tiny batch size, a few steps, and we're off.
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
max_steps=100,
learning_rate=5e-5,
optim="adamw_8bit"
)
)Step 6: Train It!
trainer_stats = trainer.train()The loss number goes down, which is the AI's way of saying: "I'm getting better at this, give me more puzzles."
Before fine-tuning, it would guess nonsense like "Nc5" even if it made no sense in the game.