Y Combinator is betting on autonomous B2B swarms, but we are authenticating them like 2008 browsers. I built an open-source, cryptographic passport using rust and python that verifies verifies the agent's identity.
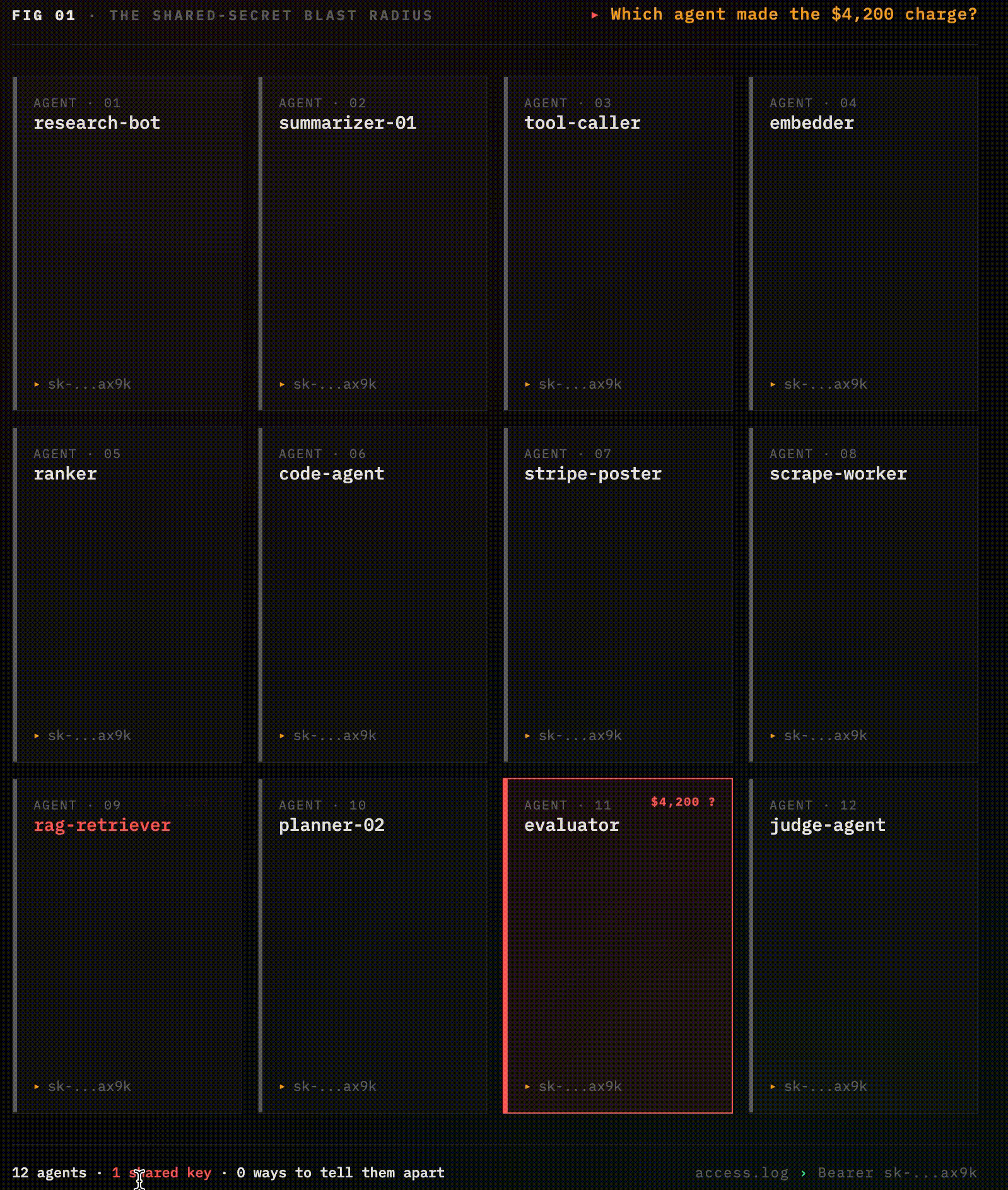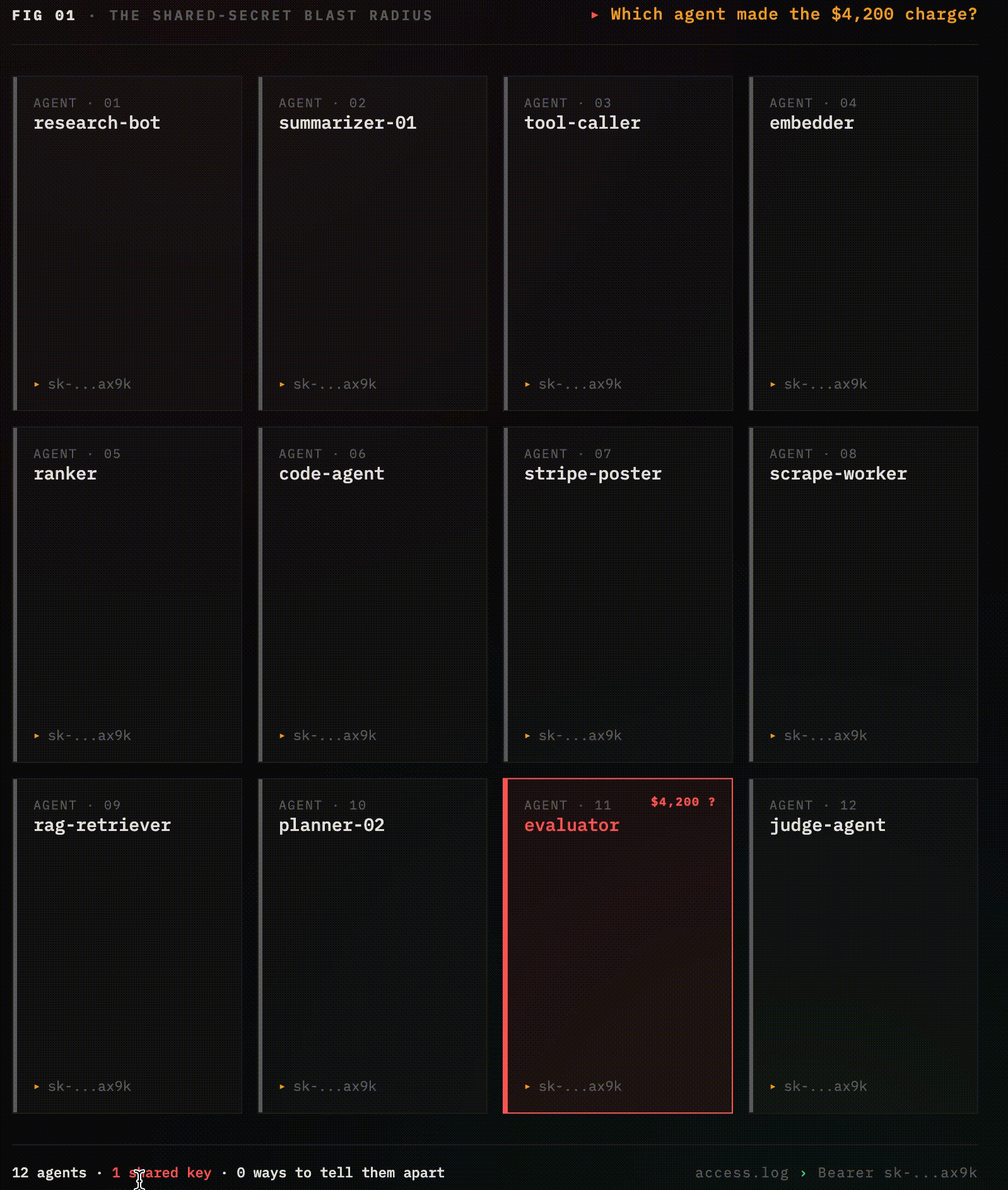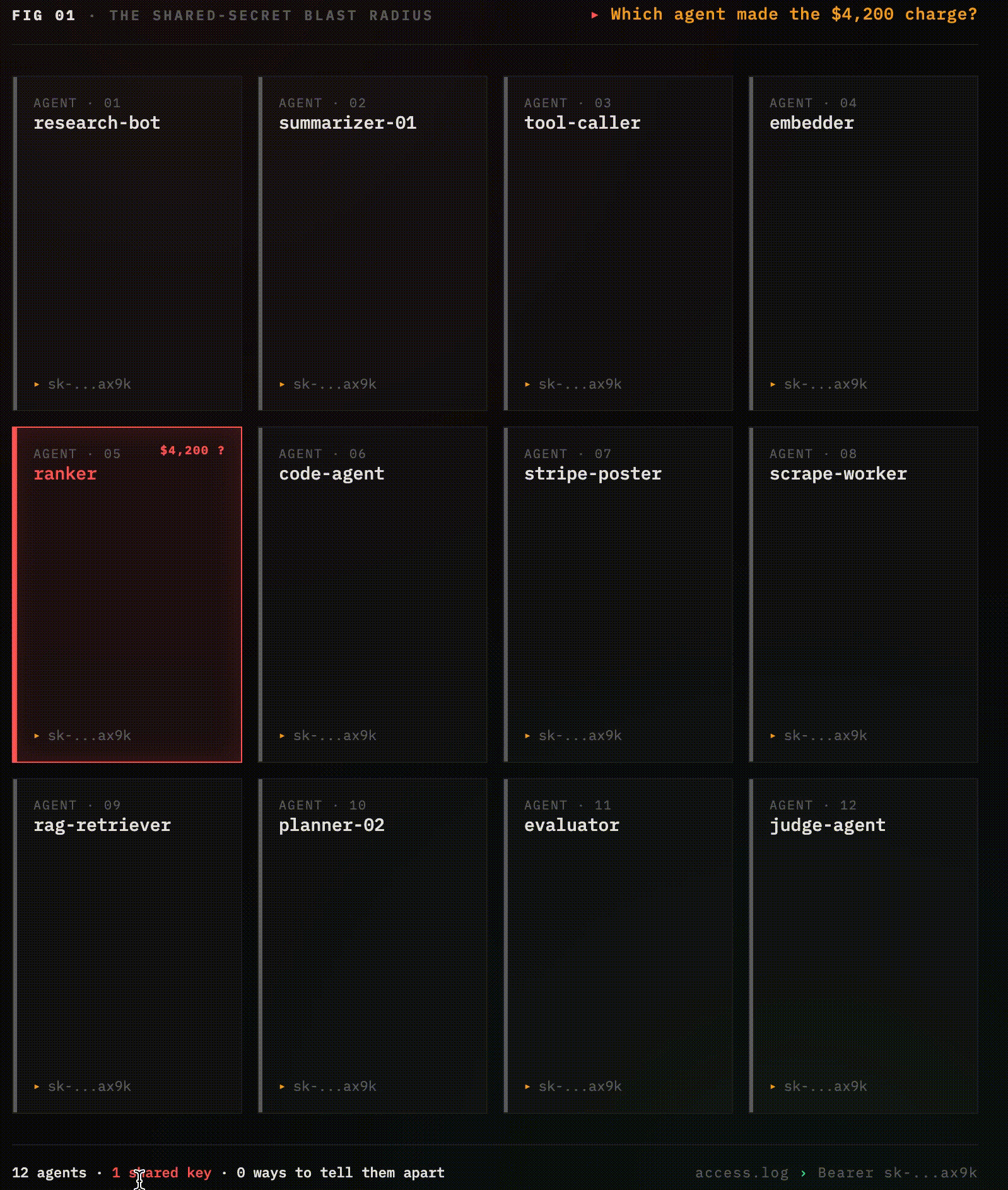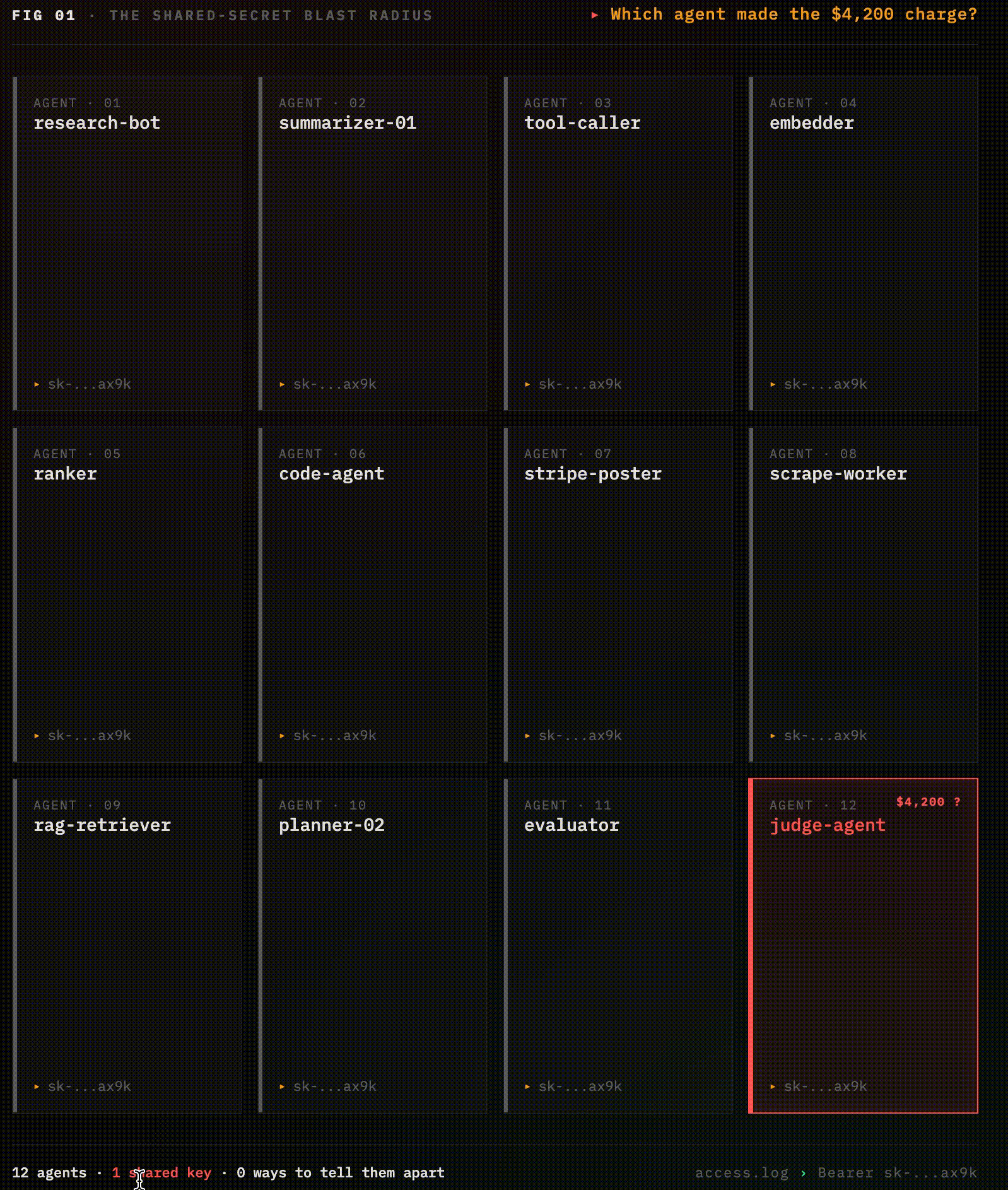
You have twelve agents in production. They all share one API key.one of them posted a $4,200 charge to the wrong Stripe endpoint, and you have no idea which one.
Access this article for free here
The access log says Bearer sk-...ax9k. So does every other access log, for every other agent, for the last six months The actual agent that made the call is invisible, it was just something in your cluster holding that secret.
You can't rotate the key without taking the entire swarm offline. You can't revoke just the misbehaving agent, there is no "agent," there's just a shared secret stamped onto every outgoing request. You can't even prove which agent did it without correlating timestamps across seven downstream services.
This is how virtually every production multi-agent system authenticates in 2026. It is the machine equivalent of shipping a web application with password: admin, except the agent does it ten thousand times an hour, across fourteen microservices, and you can't fix it without an outage.
The fix is a primitive that doesn't exist yet in the standard ecosystem: per-agent cryptographic identity. Not a service account. Not a JWT issued by your auth0 tenant. A real, small, fast, offline-verifiable identity that belongs to one agent, expires on its own, can't be replayed, and carries its own scopes and rate limits inside the signature.
That's what AgentID is. Something we built and are still building.
sk-...ax9k. image by authhorI believe the next few months of AI infrastructure will look a lot like the 2014–2016 era of cloud-native infrastructure: a Cambrian explosion of small, sharp primitives, the early CNCF landscape, etcd and Envoy and Prometheus, that compose into the eventual production stack.
Identity is the layer that has to land first. Every other primitive , rate limiting, audit, billing, delegation, capability passing — bottoms out on the question who is making this call?
The agent-native answer to that question is not a JWT issued by Auth0. It is a 173-byte Ed25519-signed binary token that any service can verify in 100 microseconds with zero network calls.
1. The False Savior: Why JWTs Don't Fit
The reflex answer is "just use JWTs." It's wrong, and the reasons are worth knowing in detail.
JWT (RFC 7519) was designed in the OAuth/OpenID Connect era for human browser sessions. Every assumption baked into the spec collapses under machine-to-machine agent traffic.
1.1. The four specific mismatches
- Size. A typical JWT runs about 800 bytes after signing with RS256. In a 40-step ReAct loop, that's 32 KB of header bytes shipped per task. At one million tasks per day, you're paying egress and ingress on 32 GB of header , bytes that contain literally zero business information.
- Verification cost. RS256 signature verification costs roughly 0.4 ms on a modern x86 core. Inside an MCP tool call that itself takes 2–5 ms, that's a 10–20% tax on every hop.
- No native rate limits. JWT has no concept of
max_calls. You bolt a counter service on top, which means an extra network hop to Redis or your rate-limit service on every request. - JWK endpoint roundtrip. First-time verification per service requires fetching the issuer's public keys from a JWKS endpoint. In a cold-started serverless agent pool, this adds 50–200 ms of latency on every fan-out.
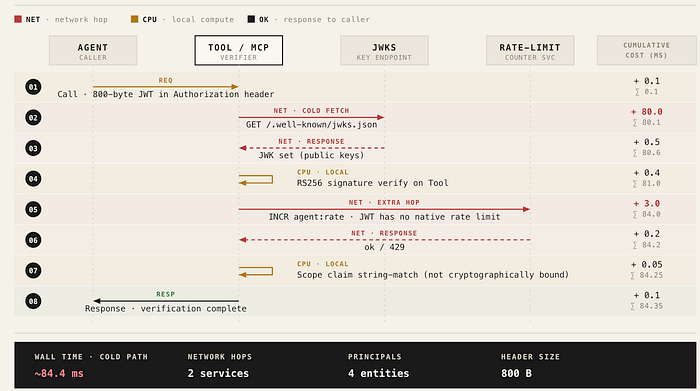
Four network principals, two network hops, ~80 ms of cold-start tax, and a separate rate-limit service, all to verify one machine call. This is what it costs to pretend an agent is a browser.
1.2.OAuth is the bigger sin
OAuth 2.x is worse, because it assumes a human consent step. Agents have no browser, no consent screen, no refresh-token flow that maps cleanly to autonomous behavior. The usual fallback, the "client credentials" grant collapses agent identity back to shared service identity, which is the original problem we started with.
The honest summary: nothing in the OAuth/JWT family was designed for a network principal that lives for fifteen minutes, makes forty calls, and then disappears. That principal needs its own primitive.
2. First Principles: What an Agent Identity Should Be
Before introducing the implementation, let's design the primitive from scratch. Five constraints, non-negotiable:
- Offline-verifiable. No JWKS endpoint. No key server. The verifier needs nothing on the network to validate a token. This is what makes the latency budget work.
- Compact. Small enough that forty nested tool calls don't dominate the bandwidth budget. Single-digit-hundred bytes, not kilobytes.
- Scoped at the signature layer. Scopes (
read:arxiv,write:notes) live inside the signed payload, not in middleware that can be misconfigured. - Rate-limited inside the token. A
max_callscounter baked into the signed structure. The token self-expires by usage, not just by clock. - Deterministically derived. Same
(name, project)tuple produces the same keypair on any machine. Identity becomes a function of configuration, not a secret to copy around.
These constraints force two engineering decisions.
2.1. Why Ed25519, not RSA or P-256
Ed25519 is the right signature scheme for this in 2026, and the case is not close:
- Speed. Ed25519 verification clocks in around 4× faster than RSA-2048 and roughly 2× faster than ECDSA P-256 on x86–64. Sub-100µs per verify on a single core is realistic.
- Size. 32-byte public key, 64-byte signature. Compare to RSA's 256-byte public key plus 256-byte signature. You can't get to a 173-byte token without it.
- No nonce footgun. Ed25519 signatures are deterministic by construction — no per-signature randomness needed. ECDSA needs RFC 6979 or a strong RNG, and the history of botched ECDSA implementations (PlayStation 3, anyone?) is not a club you want to join.
- Ecosystem alignment. SSH, age, WireGuard, Tor, Sigstore, every cloud KMS — they've all converged on Ed25519. Picking it is uncontroversial and future-proof.

2.2. Why a binary wire format, not JSON
JSON is for humans. Token verification is hot-path machine code, executed millions of times per day per service.
A binary format with fixed-offset fields means:
- No
serde_jsonallocations on the verify path. - No UTF-8 validation except on the explicit string fields (name, project, scopes).
- A single cache-hot pass parses and verifies the entire structure.
The target ,173 bytes is not arbitrary. It is the minimum size that fits a magic header, version byte, two timestamps, a call counter, a replay nonce, a 32-byte public key, length-prefixed name/project/scopes, and a 64-byte Ed25519 signature. Every byte is inside the signed region.
We'll see the layout in a moment.
3. AgentID Implementation; what we built
3.1 Repository topology
The codebase is a Cargo + Bun monorepo with one Rust crypto core and thin language bindings:
agentid/
├── core/ # Rust — `agentid-core` crate
│ ├── identity.rs # Ed25519 keypair + HKDF derivation
│ ├── token.rs # 173-byte wire format + verify()
│ ├── vault.rs # AES-256-GCM local key store
│ ├── server.rs # Optional Tonic gRPC server
│ └── napi_bindings.rs # N-API cdylib for JS/TS
├── sdk/
│ ├── python/ # PyO3 wrapper, pyproject.toml
│ └── typescript/ # Consumes the .node binary
└── cli/ # Bun + TypeScript CLI (`agentid` binary)The architectural choice is simple: the cryptography lives in exactly one place , Rust. Language SDKs are thin N-API or PyO3 shims. There is no re-implementation of Ed25519 in TypeScript. There is no "and now also verify it in Python" maintenance burden. This is the single most important architectural decision in the project, and it's invisible from the outside.
3.2. The 173-byte wire format, annotated

Three things the README doesn't spell out:
- The version byte and flags are inside the signed region. Downgrade attacks ("trick the verifier into using v0 parsing rules") become signature failures, not parser ambiguity.
token_idis the replay nonce. Stateless verifiers ignore it. Stateful verifiers — those that care about strict replay protection, keep a bloom filter or RedisSETof seen IDs scoped to the TTL window and reject duplicates. The token format supports both modes; you choose the trade-off.- Variable-length fields are length-prefixed, not null-terminated. No
strlenambiguity. No truncation attacks. No "but what if the name contains a null byte" edge cases.
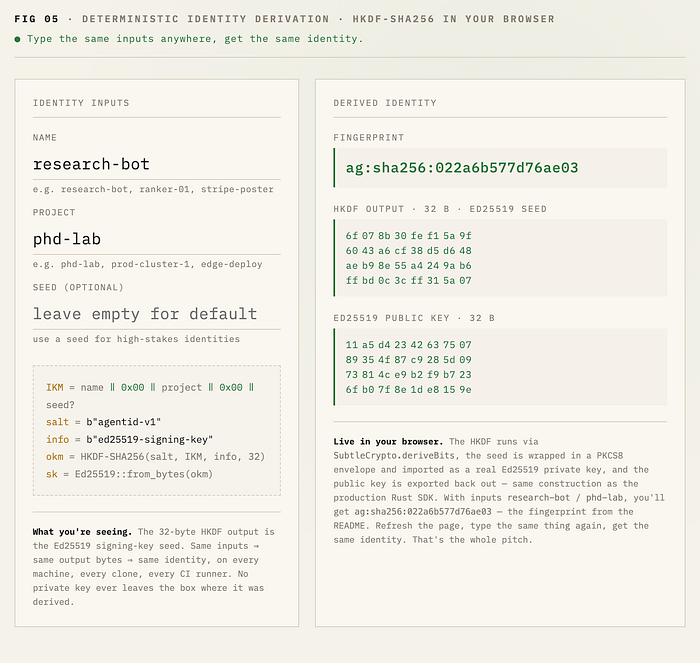
3.3. Deterministic key derivation
IKM = name ‖ 0x00 ‖ project ‖ 0x00 ‖ seed?
salt = b"agentid-v1"
info = b"ed25519-signing-key"
okm = HKDF-SHA256(salt, IKM, info, len=32)
sk = Ed25519::SigningKey::from_bytes(okm)The operational property of this construction is the thing that makes AgentID feel different from any other key system you've used:
No private key ever leaves a developer's machine, but every CI runner, every Kubernetes pod, every dev laptop can re-derive the same agent identity from the same
(name, project)tuple.
Identity becomes a function of configuration, not a secret to be copied around. You commit agent.toml with name = "research-bot" and project = "phd-lab" to your repo. Anyone who clones the repo and runs agentid keys add gets the same public key. There is nothing to leak in CI, nothing to inject as a GitHub Action secret, nothing to rotate when a contractor offboards.
If you've ever tried to share signing keys across a team and ended up with a Slack thread titled "did anyone export the new prod key to vault?", you understand why this matters.
The optional seed parameter exists for high-stakes identities where the (name, project) tuple alone shouldn't be enough to bootstrap the public key. Most users will never set it.
3.4. The local vault
Secret keys live at ~/.agentid/keys/<fingerprint>.key:
- KDF: PBKDF2-HMAC-SHA256, 200,000 iterations.
- Cipher: AES-256-GCM with a fresh nonce and authentication tag per file.
- File permissions:
0o600(user-only). - Index:
~/.agentid/index.jsonis unencrypted — it contains only public metadata: names, projects, fingerprints, and public keys. Safe to commit to a team wiki. The only encrypted thing is the private key material.
Worth being explicit about the threat model: AgentID is not an HSM-grade KMS replacement. If your threat model includes a privileged attacker on the developer machine, you want the secret material in a hardware-backed enclave (Apple Secure Enclave, TPM, YubiKey, cloud KMS). The roadmap includes pluggable backends for exactly this. The default vault is for "I want my agent identities to survive a rm -rf node_modules and not show up in a Bash history."
3.5. Developer experience :the same operation, three languages
This is the part that matters for adoption. Show the same operation across the three SDKs back-to-back and the symmetry speaks for itself.
Rust:
use agentid_core::{AgentIdentity, TokenBuilder, verify_token};
let identity = AgentIdentity::derive("research-bot", "phd-lab", None)?;
let token = TokenBuilder::new(&identity)
.scopes(["read:arxiv", "write:notes"])
.ttl_seconds(900)
.max_calls(100)
.build()?;
let claims = verify_token(&token, Some(&identity.public_key()))?;
assert!(claims.permits("read:arxiv"));TypeScript / Bun:
import { AgentIdentity, verifyToken } from "agentid";
const id = AgentIdentity.derive("research-bot", "phd-lab");
const token = id.mintToken({
scopes: ["read:arxiv", "write:notes"],
ttlSeconds: 900,
maxCalls: 100,
});
const claims = verifyToken(token, id.publicKey);
console.log(claims.fingerprint); // ag:sha256:022a6b577d76ae03Python:
from agentid import AgentIdentity, verify_token
identity = AgentIdentity.derive("research-bot", "phd-lab")
token = identity.mint_token(
scopes=["read:arxiv", "write:notes"],
ttl_seconds=900,
max_calls=100,
)
claims = verify_token(token, identity.public_key)
assert claims.permits("read:arxiv")The three snippets are not just stylistically similar , they call the same Rust function under the hood. The TypeScript path goes through N-API; the Python path goes through PyO3. There is no JavaScript Ed25519 implementation in the SDK. There is no Python cryptography library doing parallel work. One verify function, three SDK surfaces, identical behavior bit-for-bit.
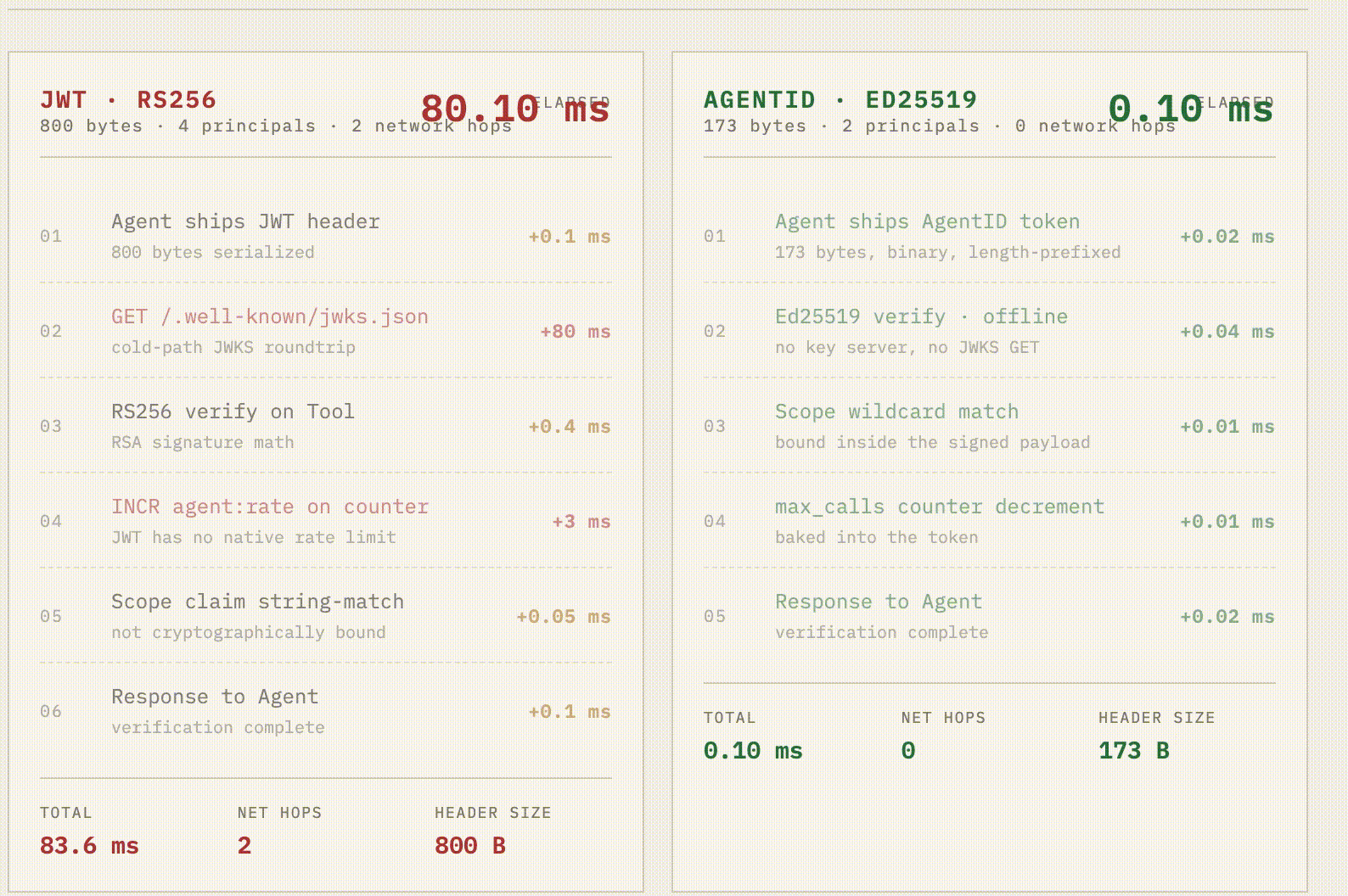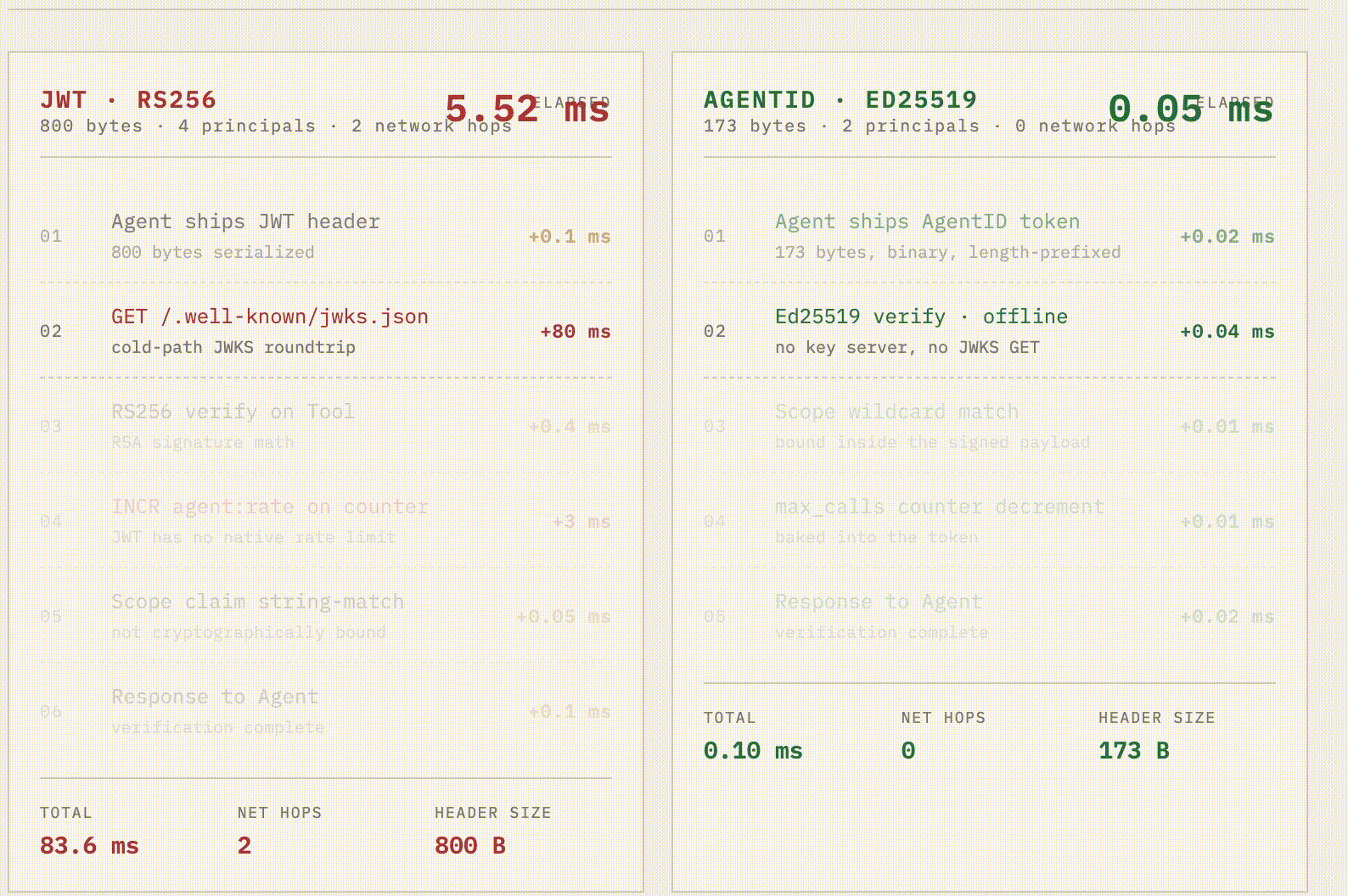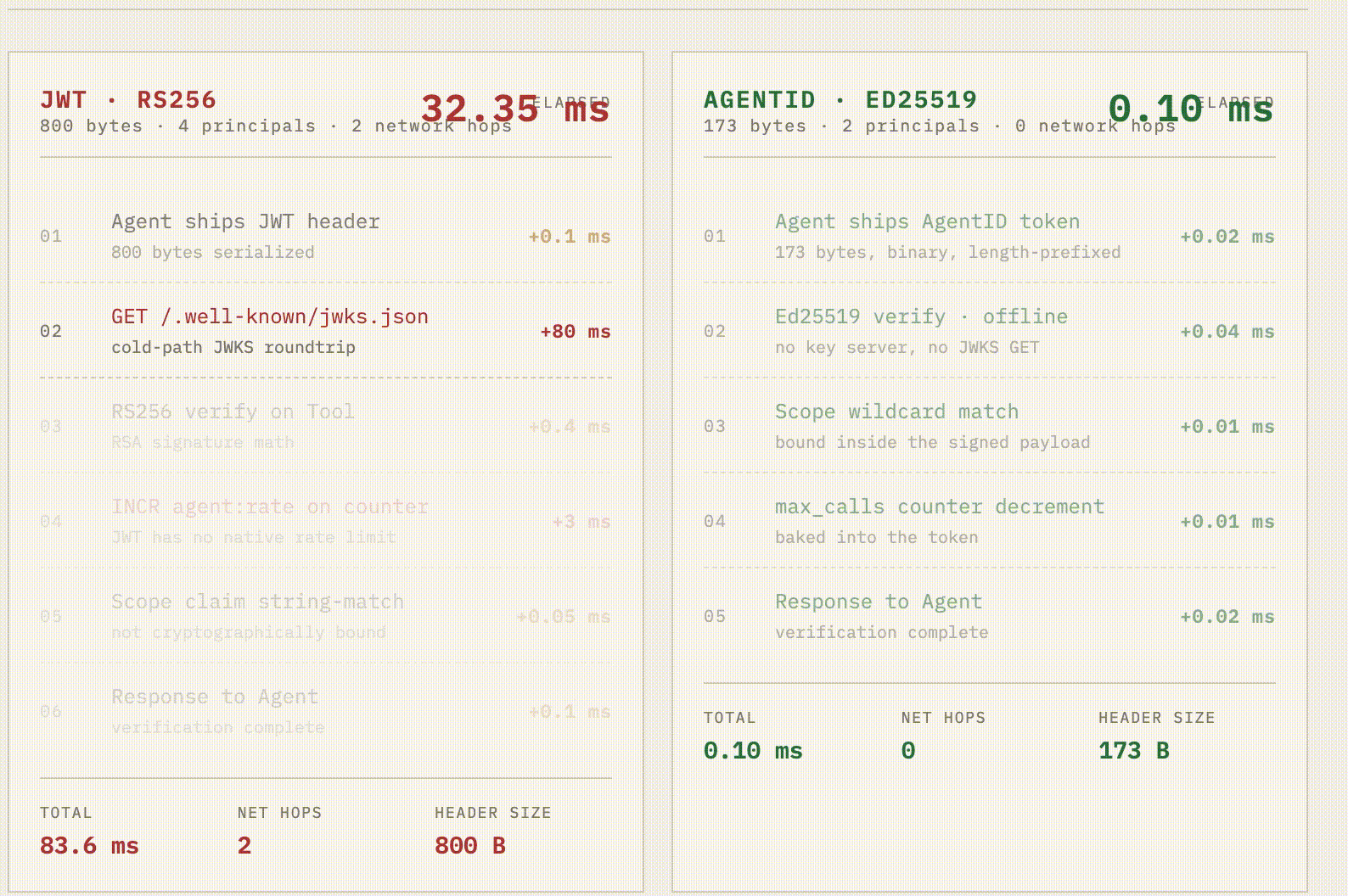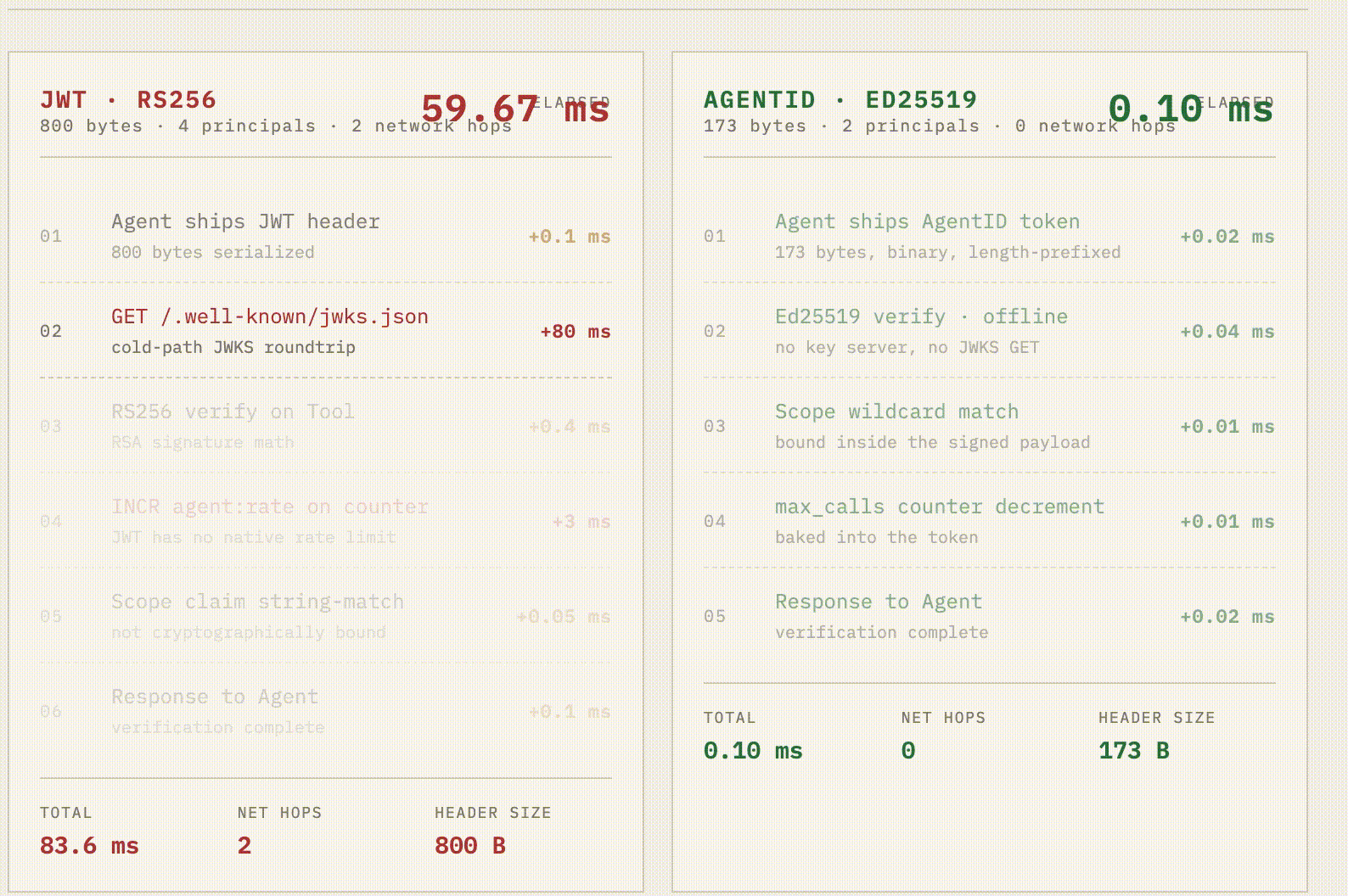
The 0.10ms verification isn't a synthetic benchmark, it's the actual cost of a native Rust ed25519-dalek verification (0.04 ms) plus zero-allocation binary parsing (0.02 ms). A pure JavaScript implementation would have burned this entire latency budget just on V8 overhead.
Meanwhile, the legacy JWT flow is hemorrhaging time: 0.4 ms for slower RS256 math, a brutal 80 ms cold-start network hop to fetch the JWKS endpoint, and another 3 ms Redis hop because JWTs lack native rate limits.
Because the Python and TS SDKs are just thin FFI shims over Rust, every agent in your fleet gets the exact same sub-100-microsecond offline verification. Zero network hops. 173 bytes on the wire.
4. The Numbers That Matter
Metric JWT (RS256) AgentID At 10M tool calls / day Token size ~800 B 173 B 6.27 GB/day saved in headers Verify time ~0.4 ms <0.1 ms ~50 CPU-minutes/day saved Network hops to verify 1+ (JWKS) 0 10M fewer JWKS GETs Cold-start tax 50–200 ms 0 ms Removed from p99 Rate limits Bolt-on service Inside token Zero extra hops Scope enforcement String claim Cryptographically bound Misconfiguration impossible
4.1. Why this matters specifically for MCP
The Model Context Protocol turns every tool into a network call. A non-trivial agent task makes 20–60 MCP calls.
At RS256 verification cost, signature math alone consumes 8–24 ms of pure overhead per task — before any actual tool work happens. At Ed25519 with offline verification, the same task pays <6 ms total, and pays it on the callee side, off the agent's critical path.
Now compound it. Agent A delegates to agents B, C, D. Each of those re-verifies. Each of those then delegates further. In a three-level fan-out with ten leaves, RS256 costs you roughly 24 ms of cumulative signature math; Ed25519 costs you under 4 ms. Multiply by the call rate. The latency advantage isn't linear — it scales with the depth of the call tree.
4.2. The bandwidth argument for edge agents
This is where on-device agents come in , the Apple Intelligence-style local tool use, Cloudflare Workers AI, the browser-resident agents that are starting to show up in 2026.
Edge runtimes are bandwidth-constrained. Six hundred and twenty-seven bytes saved per call, multiplied by N calls per session, multiplied by however many sessions are happening simultaneously on a mobile radio, this is the kind of optimization that makes the difference between "feasible on cellular" and "wifi only, sorry."
5. The Bigger Bet: The phased blueprint
- v0.1 (today): primitives. Identity, token, vault, gRPC. The knife.
- v0.2: framework middleware (LangGraph, CrewAI), revocation lists, key rotation. The integration surface.
- v0.3: AgentID Cloud , hosted key management, audit log, team dashboard. The commercial layer.
The structural point: the open-source primitive ships first, and stays useful forever, even if the cloud layer never exists. There is no bait-and-switch. The local-only path is the intended deployment for most users. The cloud product is for teams that have moved past the local-vault stage and need centralized audit and rotation. Both run on the same wire format. Both use the same Rust core. Neither requires the other.
I need you to try it, break it, and tell me where I'm wrong.
This is an active attempt to solve a massive infrastructure gap, and I want early feedback. If you think the wire format is wrong, tell me. If you think Ed25519 is the wrong choice in 2026, tell me. If you've shipped agent infrastructure and you think my threat model has a gap, especially tell me.The repo is here. The crate is on crates.io as agentid-core. The TypeScript SDK is on npm as agentid. The Python package is on PyPI as agentidentity-auth.
If you build agent infrastructure for a living and any part of this resonated, or any part of it pissed you off ; open an issue. I'd rather have the argument now than after v1.0 is locked in.
It is one primitive, with one job: prove this agent is who it says it is, with these scopes, for this long, in 173 bytes.
That's the whole pitch. Everything else is a roadmap item.
This is just phase 1 of building the open-source agent infrastructure stack. If you found this architectural breakdown useful, follow me for the next part where we tackle persistent agent memory. All my socials can be found. on my wesbite if you wish to contact me or know more about what i build.
If you build agent infrastructure and want to help validate this primitive, or if you just appreciate a clean piece of Rust, star this repo, and check out the pypi package and rust crate here!