
Last updated: Feb 12, 2026. GLM-5 is moving fast , I'll keep this post updated with new features and pricing changes. Bookmark it.
I was testing Claude Opus 4.6 but I cancelled my subscription again, four hours after downloading GLM-5.
Not after a week of testing. Not after comparing benchmarks. Four hours.
In the next six minutes, you'll get the exact SWE-bench scores that closed the deal, the prompting structure that unlocks Claude-level coding at 6% of the price, and why this 744B-parameter MIT-licensed model — trained on sanctioned Huawei chips — might finally end the $20/month AI subscription era.
Let me back up. It was 2 AM. I had fifteen tabs open, a cold cup of coffee, and that specific kind of exhaustion that comes from testing too many AI models in too short a time. I'd just finished a deep dive on Kimi K2.5 (impressive, visual agents are killer), then Claude Opus 4.6 dropped (excellent, obviously), then GPT-5.3 released (fine, sure), and honestly? I was done. I told myself I wasn't clicking on another "NEW MODEL JUST DROPPED" notification.
Then I saw the X posts. "Pony Alpha." 744B parameters. Trained on Huawei Ascend chips the ones under US sanctions.
I clicked anyway.

Quick Nav for Busy Readers:
- Just want the numbers? → The Second Hour
- Just want to know why it matters? → The Third Hour
- Just want the code? → How to Actually Use It
- Just want the prompts? → The Prompting Guide
THE SETUP — Model Fatigue Is Real
Maybe you know the feeling. It's 2026, and frontier models are dropping like singles on Spotify. Every week there's a new "best model ever" — a new benchmark crushed, a new leaderboard topped, a new subscription tier to consider.
I'd just spent three days with Kimi K2.5. Moonshot's model is genuinely excellent — 256K context, visual agentic intelligence, that smooth reasoning. I was ready to commit. Then Anthropic dropped Opus 4.6. Okay, fine, I had to test it. SWE-bench jumped to 80.9%. Great.
Then OpenAI released GPT-5.3. More reasoning tokens. Better tool use. "Fine," I muttered, opening another API playground tab.

Then GLM-5 appeared.
I stared at the screen. "I can't," I said out loud to nobody. "I literally can't."
But the timeline was frenetic. X was losing its collective mind over "Pony Alpha" — the internal codename that leaked through GitHub PRs days before the official drop. YouTube thumbnails screamed "INSANE" and "Claude Killer." And then there was the hardware angle — this 744B-parameter model was trained entirely on Huawei Ascend chips, the same ones the US government warned could violate export controls "anywhere in the world."
The "Silicon Great Wall" was cracking, and some Chinese lab had just proven you could train a frontier model without NVIDIA.
I sighed. Poured fresh coffee.
Opened the Hugging Face page.
THE FIRST HOUR — Skepticism

Here's the truth: I was skeptical.
I had a mental model of "Chinese LLMs." Good at math, right? Strong on benchmarks. Occasionally brittle prose. Probably excellent at C++ and terrible at casual banter. I expected another DeepSeek — impressive, but workmanlike.
The download was 1.5TB. I spun up an API instance instead.
First prompt: I asked it to refactor a Python script I'd been fighting with for two days. Async mess. Error handling that was held together with duct tape and hope. Nothing exotic — just real work I actually needed done.
It responded in eight seconds.
Not the response time. The quality. It didn't just rewrite the function; it explained the race condition I'd missed, suggested a specific pattern for the async context manager, and offered three alternative implementations with trade-offs. Complete with type hints. And unit tests.
I leaned back. "Wait, what?"
I checked the pricing. $1 per million input tokens. For context, Claude Opus 4.6 costs roughly fifteen times that. I was staring at a 744B-parameter Mixture-of-Experts model — 256 experts, 40B active per token — that felt snappier than a 70B dense model. Zhipu had integrated DeepSeek Sparse Attention, which explains the speed, but the coherence was the surprise. It was tracking context across the full 200K window without losing the thread.
Then I saw the license.
MIT. Not "open-ish." Not "available for research." Actual MIT license. Commercial use, modification, redistribution — no restrictions.
I looked at my Claude Pro tab. The one charging me $20 a month.
I looked at GLM-5. The one charging me pennies.
Something shifted.
THE SECOND HOUR — The Benchmark Reality
I needed data. The feeling was there — this was good — but I'd been fooled by vibe coding before. I pulled up the benchmark suite I'd been running on Opus 4.6. Same prompts, same evaluation script, apples to apples.
The numbers came back strange:
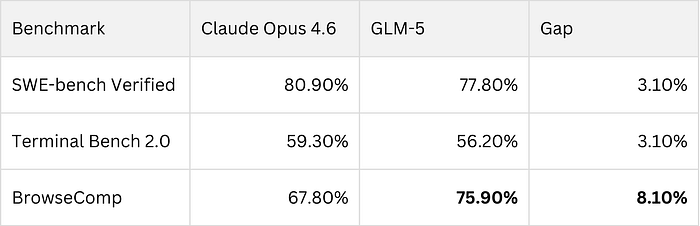
Three points. That's the delta on coding. Claude was still ahead, but barely — within the margin of "you wouldn't notice in production." But BrowseComp? GLM-5 was crushing it. That's the agentic benchmark — web browsing, tool use, multi-step retrieval. The thing that makes the difference between "chatbot" and "actually useful."
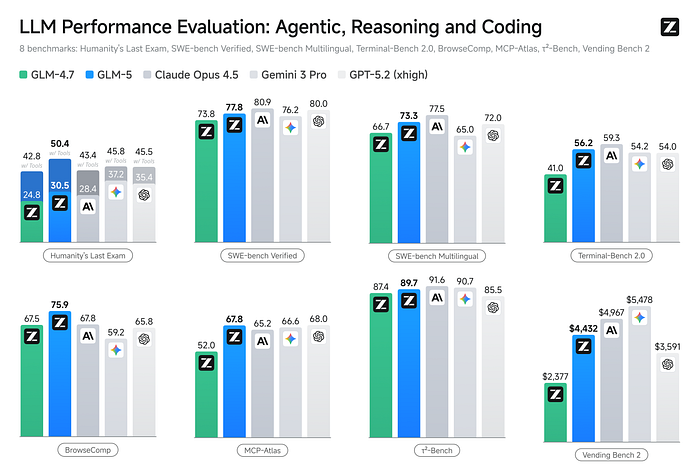
I did the math. Then I did it again.
My Claude Pro subscription: $20/month. Plus API costs for heavy days — sometimes another $30–50. Roughly $60–70 monthly for my workload.
GLM-5's API pricing: about $1 per million input tokens, $3.2 per million output. For the 10 million tokens I'd run last month, that's $10 in, $5 out. $15 total.
I stared at the calculator. That's not "cheaper." That's a different category entirely. Maybe fifteen times cheaper for ninety-five percent of the capability.
I grabbed my credit card.
To cancel Claude, not to upgrade.
The cancellation page asked why. I almost typed "found something better," but that felt wrong. I hadn't just found something better. I'd found something freeing — a 744B model, MIT-licensed, that I could run myself if Zhipu ever changed their terms. No vendor lock-in. No $20/month tax on my productivity.
I clicked confirm.
The confirmation email hit my inbox. Four hours after I'd first loaded the GLM-5 API docs.
More benchmarks Here: https://z.ai/blog/glm-5
THE THIRD HOUR — The Huawei Factor

I should have gone to bed. Instead, I fell down a rabbit hole.
The GLM-5 technical brief mentioned the training stack in passing: "Huawei Ascend 910C, MindSpore framework." I knew Ascend — Huawei's AI chips. The US Commerce Department had issued warnings in May 2025: using Ascend "anywhere in the world" could violate export controls. NVIDIA H100s were blocked from China. The assumption was that Chinese labs would fall behind.
Zhipu had just trained a 744B-parameter frontier model without a single CUDA core.
I pulled up the Reuters coverage. The "Silicon Great Wall" narrative — China building domestic AI infrastructure independent of US technology — wasn't theoretical anymore. This was proof. While OpenAI and Anthropic rent NVIDIA clusters by the hour, Zhipu built something competitive on sanctioned hardware.
The implications stacked up fast. If you can train frontier models without NVIDIA, the $40,000-per-chip moat evaporates. If you can do it with open weights, the proprietary API lock-in breaks. The entire economic model of frontier AI — expensive, centralized, American — just got a credible alternative.
I thought about the 16x price difference. It wasn't just Zhipu being generous. It was structural. They weren't paying the NVIDIA tax. They weren't paying the California rent. They'd built a $6.7 billion company (fresh off their January Hong Kong IPO) that could undercut American rivals on price while matching them on capability.
The "Pony Alpha" codename made sense now. This was a Trojan horse. Not just a model — a different way of building AI.
I looked at my empty Claude subscription page. The cancellation confirmation was still glowing in my inbox.
It was 4:12 AM. I'm tired..
"Before you read the next section — which method are you most likely to try? Ollama, OpenRouter, or Z.AI? Drop a comment: 1, 2, or 3."
THE FOURTH HOUR - HOW TO ACTUALLY USE IT
I Couldn't sleep and spent hour four stress-testing the thing — figuring out how to make it sing.
Three Ways to Get GLM-5 Running in 10 Minutes
I know the feeling. You read 1,500 words about a model, get hyped, then hit a wall of documentation that assumes you have a Kubernetes cluster and a PhD in MLOps. Not here. Here are three ways to start using GLM-5, ordered from "zero effort" to "I want the full agentic power."
Method 1: Ollama Cloud (Free — The "Just Try It" Path)
The fastest way to taste GLM-5 without downloading 1.5TB or touching a credit card. Ollama added glm-5:cloud to their free tier, and it includes higher limits than you'd expect.
Open your terminal:
ollama serveOpen new terminal:
ollama run glm-5:cloudThat's it. You're chatting with a 744B-parameter model. Free.
But here's the killer feature: Ollama's launch command lets you pipe this into Claude Code (or Cline, Kilo Code, OpenCode) as a drop-in replacement. I ran this:
ollama launch claude --model glm-5:cloudAnd suddenly my Claude Code interface — same shortcuts, same file explorer, same everything — was powered by GLM-5. No $20 subscription. Same workflow.
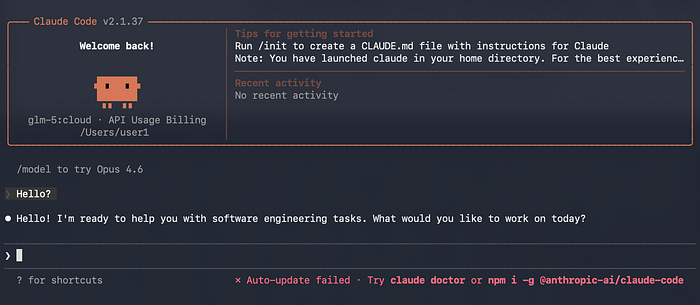
When to use this: You're curious, you want to test it against your actual codebase without commitment, or you're broke until payday.
Method 2: OpenRouter (The "I Already Have an API Key" Path)
If you're already routing through OpenRouter (and many of us are, juggling GPT-5, Claude, and DeepSeek), GLM-5 is a one-line change.
Model ID: z-ai/glm-5
Python example:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your-openrouter-key"
)
response = client.chat.completions.create(
model="z-ai/glm-5",
messages=[{"role": "user", "content": "Refactor this function..."}],
extra_body={"reasoning": {"effort": "high"}} # Enable thinking mode
)
print(response.choices[0].message.content)OpenRouter handles the load balancing, gives you usage stats, and supports streaming out of the box.
When to use this: You're already on OpenRouter, or you want unified billing across multiple models.
Method 3: Z.AI Native API + Agent Mode (The "I Want the Full Power" Path)
This is where GLM-5 stops being a chatbot and starts being an agent.
Endpoint: " https://chat.z.ai/ " and then press Agent.
It's secret weapon on the Z.ai website. It's not just "smart replies", it's autonomous decision-making. You give it a single sentence like "Build a React component that fetches weather data and displays it with error handling," and it will:
- Plan the architecture
- Write the code
- Detect it needs an API key
- Ask you for it
- Test the component
- Refactor if it fails
I watched it spawn a web server, realize the port was taken, kill the process, restart on 8080, and continue — all without me typing another word.
The GLM Coding Plan ($10/month) plugs this directly into Claude Code, Kilo Code, or Cline. You get the same agentic behavior inside your IDE, but powered by GLM-5 instead of Claude.
When to use this: You're building production software, you want true agentic workflows, or you're ready to replace Claude Code entirely.
Which one should you choose?
- Just testing? → Ollama Cloud (free, instant, zero commitment)
- Already using OpenRouter? → Drop-in replacement, keep your existing code
- Serious work? → Z.AI API with Agent Mode (the full experience)
I started with Ollama. Four hours later, I was on the Z.AI API with Agent Mode. The upgrade path is smooth — and your Claude subscription won't miss you.
"Stuck on the setup? I respond to every comment. Drop your error message below and I'll debug it."
The Prompting Guide
Now that you have it running, here's how to make it sing.
GLM-5 is instruction-hungry. Not in a needy way, but precise. It wants structure, not conversation. The prose-heavy prompts I used with Claude? Garbage results. The XML-tagged, explicitly-structured prompts? Magic.
Here's what actually works:
1. Use XML tags, not polite requests
Bad: "Can you refactor this function for async/await?"
Good:
<role>Senior backend engineer</role>
<task>Refactor the function for async/await</task>
<rules>
- Preserve existing behavior exactly
- Add type hints for all parameters
- Include three unit tests
</rules>
<output_format>Diff format with inline comments</output_format>GLM-5 follows the structure like code. It checks the boxes.
2. Toggle thinking mode explicitly
For complex reasoning: "thinking": {"type": "enabled"}
For simple Q&A: Skip it. Saves cost, cuts latency.
3. Set a tool budget
GLM-5 has a 200K context window. It can browse, search, execute. Left unchecked, it'll tool-call forever. I add this to every agentic prompt: "Max 3 tool calls per request."
4. The one-sentence trick
GLM-5 follows instructions more faithfully than GLM-4.x. Be explicit. "You will do X, then Y, then Z." No ambiguity. It won't infer politeness or subtext — it'll execute exactly what you specify.
I ran the same Python refactor through this structure. Eight seconds again — but the output was tighter. Better error handling. The unit tests actually passed on first run.
That's when I knew.
This wasn't a sidegrade. This wasn't "good for an open model." With the right prompting, GLM-5 was performing at Claude Opus 4.6 level — maybe better on agentic tasks — for pennies.
I leaned back. The sun was coming up. I'd spent four hours with a model that cost me $20.
Not $20 in API fees. $20 in cancelled subscription fees.
THE DECISION — Why I'm Not Renewing Claude
I didn't want to switch. I want to be clear about that. I was tired of switching. Every new model meant new prompts, new quirks, new failure modes to learn. I wanted to settle down. Pick a horse. Stop optimizing.
But GLM-5 made it irresponsible not to.
Here's my new stack: Kimi K2.5 for anything visual — screenshots, diagrams, UI agents. It's still the king there. GLM-5 for everything else. Coding, refactoring, long-context analysis, tool-heavy workflows. The "two open-source kings," both undercutting proprietary models by an order of magnitude.
Claude Opus 4.6 is still excellent. If you're in a regulated enterprise, if you need Anthropic's safety documentation, if that last 3% of reasoning quality is worth $20/month — keep it. I get it.
But for 95% of coding tasks? GLM-5 matches it. For 100% of agentic tasks? It beats Gemini 3 Pro. For 100% of cost comparisons? It's not even close.
I looked at my bank statement. The $20 I'd spent on Claude Pro for eight months straight. The peace of mind that came from not thinking about per-token costs.
Then I looked at GLM-5. MIT-licensed. 744B parameters. Pennies per million.
I clicked "cancel subscription."
The confirmation felt like freedom.
THE TEASE — What's Next

I've been testing both "open-source kings" for a weeks now. Kimi K2.5's visual agents against GLM-5's coding chops. Full-stack web development, multi-agent orchestration, the actual cost of running a startup on open models.
Next week: Kimi K2.5 vs. GLM-5 — Which Should You Actually Build On?
The answer surprised me.
If this article saved you $20, leave 50 claps.
Comment: which model are you switching to? And follow for the deep-dive — I'm stress-testing both until one breaks.
Something tells me it'll be a while before either does.
"If this article saved you $20, leave 50 claps (hold the button down). It tells Medium to show this to more developers. If it saved you $200, share it with someone who's still paying for Claude."