
Let's be real, numbers don't lie.
While markets rally with AI, its effect is clearly not being translated into value, as fewer than 4% of companies are using AI to produce goods and services.
To make matters worse, while some big companies are indeed embracing AI, the unfathomable costs prevent smaller companies from following suit, ironically turning a technology meant to democratize complex tasks and foster competitiveness into a massive inequality machine.
However, things might soon change, as Microsoft has quietly released a 1.58-bit Large Language Model (LLM) that matches the performance of its 16-bit counterpart while being an order of magnitude cheaper and faster.
Microsoft calls it the era of 1-bit LLMs, and you are going to love every second of it.
This insight and others have mostly been previously shared in my weekly newsletter, TheTechOasis.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝
No Money, No Party
Despite the impressive results AI is achieving at the research level, it's suffering from several illnesses such as economics, environmental impact, and absence of value that prevent it from becoming what incumbents have predicted it to be.
The numbers don't add up
Even today, AI adoption across corporations hasn't reached double digits, as proven by a recent study by the National Bureau of Economic Research and echoed by MIT.
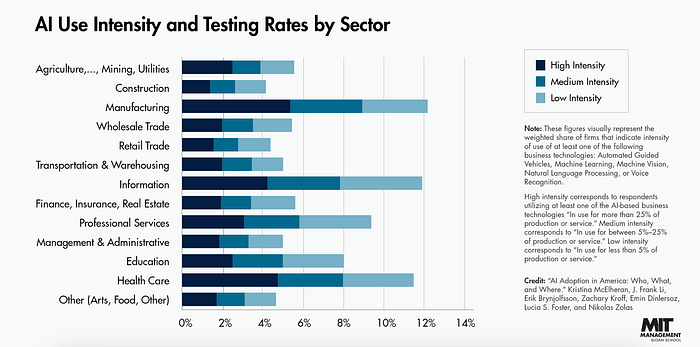
But the study shows a much more worrisome sign, which is the clear imbalance between big corporations and the rest.
Adding insult to injury, it also showcased that the unevenness wasn't only about size, but also sectors and even geographical locations.
Kristina McElheran from the University of Toronto summed it best:
"The digital age has arrived, but it has arrived unevenly."
But that's far from being the only issue. It's also terrible for the environment.
If we consider that the AI industry's carbon footprint is already around 1% of the global emissions according to the University of Massachusetts Amherst, and acknowledging that AI workloads are going to scale massively over the next years, then we must all agree we have a problem.
Simply put, unless we figure out a way of making AI an efficient technology, its impact and value generation will be limited to large corporations, while the rest of us build fun toys that rap about Texan barbeque in Shakespearean style.
However, the opportunity for value remains brutal due to the paradigm shift that Generative AI has brought on us, the Ƈ-to-many' age.
The Foundation Paradigm
The biggest reason that explains AI's success today is none other than foundation models (FMs), models that can perform a wide range of different downstream tasks.
By creating huge foundation AI models we obtained a series of benefits, mainly generalization, that turned AI into a technology with higher chances of success — before AI had a 90% failure rate according to Gartner — and more attractive returns.
Finally, AI did not require training to learn, as you simply had to ground the model into each use case by providing it with the necessary (and often private) data in real time, a process formally known as prompt engineering.
But our biggest success is also our biggest burden.
Money Bound
Frontier AI models require very expensive hardware to run, GPUs, due to their parallelization capabilities.
Despite the fundamentalness of GPUs, the relationship between LLMs and these pieces of hardware is far from ideal.
For starters, the size of most models today doesn't fit in one single GPU. Our current best GPUs, like NVIDIA's H100 or Intel's Gaudi 2, only have 80GB and 96GB of High-Memory bandwidth (HBM) respectively.
Might seem like a lot, but we are talking about models that, in extreme cases like ChatGPT or Gemini Ultra, might be in the TeraByte size range.
Consequently, we must 'break down' the model into parts using distributed computing methods like FSDP, where the model's layers are separated by groups into units, each assigned to a single or set of GPUs.
Couldn't we just store the model in Flash or HDD?
In theory, we can't. The entire model is run for every single prediction, meaning that the weights need to be accessible to the GPU cores, otherwise the retrieval process takes to long and latencies would be unbearable.
An interesting line of research is being pushed by Apple with 'Flash LLMs' stored in the much more abundant flash memory by including a predictor that, for every input data, predicts what parts of the LLM are required to be in RAM memory, allowing for massive models to fit into hardware like iPhones.
FSDP partially solves the distributing problem, but adds communication overhead as the GPUs need to share their computations both for training and inference.
And if things were not sufficiently complicated, the arrangement of GPUs also matters.
Currently, the most exciting approach is Ring Attention, where GPUs are set on a ring to overlap individual GPU computation with GPU-by-GPU communication overhead so that the global prediction time isn't constrained by the distributed nature of the workloads.
Meanwhile, companies like Predibase are offering simple serverless frameworks where you can store multiple models into one GPU dramatically reducing your costs, and other organizations like Groq are even suggesting that we shouldn't be using GPUs at all for inference workloads by proposing Language Processing Units (LPUs) with insane speeds.
Yet, no matter the approach, the key issue still stands, LLMs are much, much bigger than the ideal, and all the previous innovations are centered around the problem of dealing with large model sizes.
For that reason, considering that memory requirements are the main bottleneck, a very popular solution these days is to quantize the model.
And here, finally, is where Microsoft's 1-bit LLMs come in.
1.58 Bits That Could Change the World
First and foremost, what on Earth is quantization?
The Precision Question
Quantization is the process of reducing the storing precision of the parameters (weights) of the model to downsize it and save memory, the main bottleneck of these models as we discussed earlier.
Most current LLMs train their models using 16-bit, or 2-byte precisions. In other words, each weight in the model occupies exactly 2 bytes in memory.
It must be said that some parameters of the model, like the optimizer states used during training, are stored in full precision (4 bytes), but the great majority are stored in 2 bytes.
There are different methods, but the concept is always the same, compressing the values of the weights into smaller bit sizes.
A very common approach is to take a 16-bit weight and turn it into a 4-bit value. At this point, it may seem unclear what's the real impact, but bear with me with the following example.
If we take an already-trained 50-billion-parameter LLM, a fairly small model by today's standards, at a 2-byte precision, our model weighs 100 GB.
To simplify the example, I am assuming a model that is already trained for short sequences so that the KV cache, a memory requirement with a huge impact for long sequences, is negligible.
Consequently, you automatically need at least two NVIDIA H100 GPUs just to store the model.
But if you quantize the weights to 4-bit, you essentially divide by 4 the memory requirements, so the model is suddenly 'just' 25GB, fitting perfectly in a single GPU.
But if this is so incredible, why not do it always?
The post-training trade-off
Most quantization procedures today are performed post-training. That is, training the model at a mixed or full precision (2 or 4 bytes) and then quantizing the model.
The procedure alone is already an issue because this will irrevocably have a considerable impact on performance.
Imagine you train for a long time with a huge tennis racket and, suddenly, before the match starts, they give you a much smaller one. Naturally, you are going to have a hard time hitting the ball.
Well, with post-training quantization we are doing the same thing to the model, basically.
But what if we train the model from scratch while it's quantized?
This is what Microsoft is pushing, but taken to the extreme.
The future of AI?
In simple terms, Microsoft's paper proposes a radical approach by reducing the per-weight memory allocation from 16-bit to 1.58-bit, an approximate 16-time reduction in memory requirements.
In other words, all weights in the linear layers will have a value Ƈ', '-1', or Ɔ'.
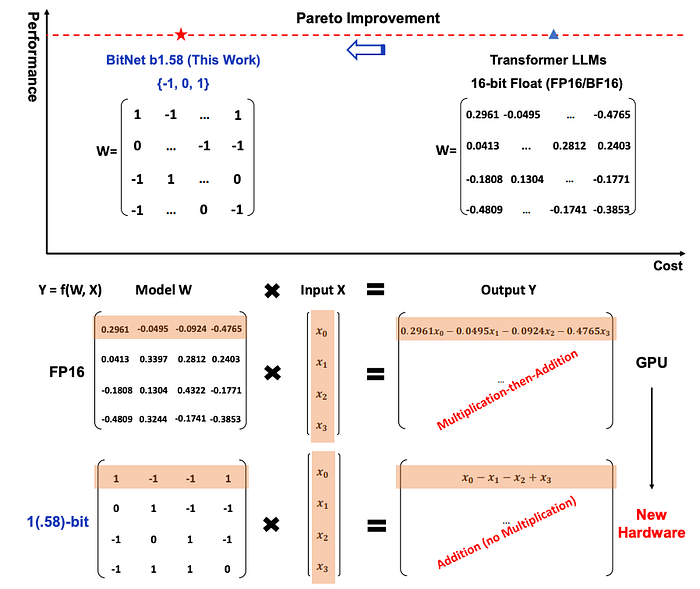
They only focus on feedforward weights, while keeping standard activations and attention at 8 bits, as the greatest amount of computation and memory requirements accumulate on the feedforward layers, not in attention.
But the key point to outline about Microsoft's approach is that it's "quantization-aware", meaning they train the model from scratch while applying the quantization in parallel.
That way, instead of training a model at a certain precision and then clipping its values afterward, you train the model in a quantized form from scratch.
Another element worth noting is that, by having these weights as a +/- 1 or a 0, you essentially avoid matrix multiplication.
But why is this so relevant?
As multiplying by 1 or -1 boils down to applying the sign function on the other number, and 0 eliminates that number from the equation, your matrix multiplications turn into matrix additions (as shown in the image above) considerably reducing the computational requirements.
And contrary to what we might expect, this compromise hasn't had an impact on performance, quite the opposite.
Speed surges, but quality does not degrade
When compared to models with similar weight counts, the model not only performs well, but outcompetes its counterpart on most benchmarks.
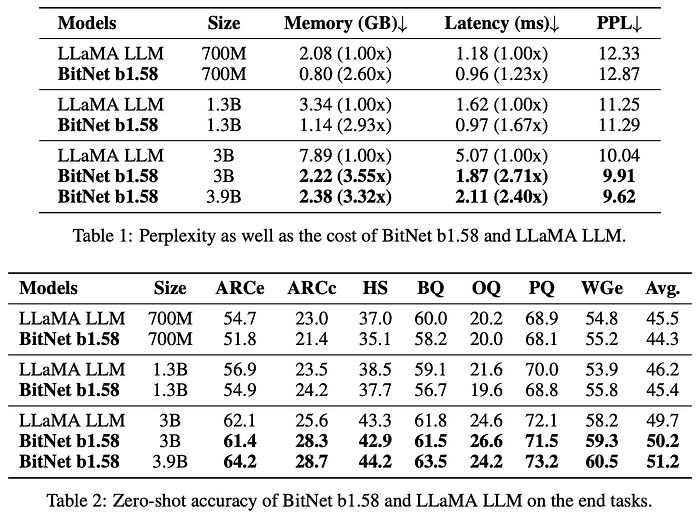
PPL stands for perplexity, it's the main objective measurement of LLM quality, measuring how 'perplex' a model is. In other words, the higher the probability it assigns to the correct token, the less perplex the model is.
Researchers then claim that the main benefits of this approach apply to any other size and become more apparent with scale, meaning that:
- "13B BitNet b1.58 is more efficient, in terms of latency, memory usage, and energy consumption, than 3B FP16 LLM."
- "30B BitNet b1.58 is more efficient, in terms of latency, memory usage, and energy consumption, than 7B FP16 LLM."
- "70B BitNet b1.58 is more efficient, in terms of latency, memory usage, and energy consumption, than 13B FP16 LLM."
As you can see, quantization-aware training develops its own scaling laws, as the bigger the model, the bigger the impact.
And when comparing across equal sizes, the quantized LLM allows for 11 times larger batch sizes (the number of individual sequences you can send the model) with a 9 times increase in tokens per second generation.

But what does all this mean then?
In short, we might have figured out a way to train frontier AI models more efficiently while not compromising performance.
If so, we could soon see 1-bit LLMs becoming the norm, and workloads that would require insurmountable expenditures and huge data centers could eventually be run on consumer hardware or, even, on your smartphone.
For example, we could potentially have +100-billion-parameter models run in your iPhone, and that number would grow into the +300 range for state-of-the-art laptops (assuming they have the necessary GPUs, naturally, which is already the case in most premium consumer-end hardware).
But we can even take this a step further.
Soon, your digital products like your smartphone could be infused with multiple different LLMs running in parallel, each specialized in its downstream task, which could make LLMs even more ubiquitous in our lives.
An LLM to handle your email, an LLM to handle your notifications, an LLM to edit your photos... you name it.
If this doesn't represent the essence of AI value creation, then I don't know what to tell you.
The Year of Reckoning for AI
At the beginning of the year, I predicted that 2024 would be more about these kinds of innovations and less about 'GPT-27', and this kind of research points us that way.
And considering that we have yet to develop the tools to confidently control and align the super models of the future currently being developed in top AI labs, let's hope that is the case.
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.