
Hallucinations are a significant issue with today's LLMs. The word "hallucination" usually means generated text that contains plausible but factually incorrect information.
Hallucinations undermine the trustworthiness and safety of real-world LLM applications. But what actually causes hallucinations?
In this article, we will examine some of the causes of hallucinations and, based on that information, discuss ways in which we, as users, can avoid triggering them.
What Are LLM Hallucinations?
The word hallucination is now used so widely in the context of AI that it has made its way into dictionaries. Merriam-Webster defines it as follows:
Hallucination: a plausible but false or misleading response generated by an artificial intelligence algorithm
In the context of LLMs, a hallucination is a seemingly plausible response that is actually factually incorrect. These statements are often delivered with high confidence, making them difficult to detect. For instance, an LLM may fabricate facts or cite nonexistent sources.
Several recent cases have shown lawyers getting into trouble for relying on generative AI that has fabricated legal citations. One high-profile example is when two Morgan & Morgan attorneys used an AI tool that hallucinated fake cases in a lawsuit against Walmart [1].
Whereas a human would naturally say "I don't know" or hedge with phrases like "I'm not entirely sure" or "I think…," LLMs often produce a confident but incorrect answer instead.
Types of Hallucinations: Intrinsic vs. Extrinsic
Researchers sometimes distinguish between intrinsic and extrinsic hallucinations [2]:
- Intrinsic hallucinations occur when the model provides information that contradicts what is already present in the input context. For instance, when summarizing a document, the model may alter details that were explicitly stated.
- Extrinsic hallucinations occur when the model introduces new information not grounded in the input context. For instance, a summary may invent facts not found in the given document.
Extrinsic hallucinations are usually the more impactful problem, especially when we ask an LLM open-ended questions without providing background context. Intrinsic hallucinations are typically less problematic, which is why techniques such as Retrieval-Augmented Generation (RAG) that inject relevant knowledge into the prompt are effective in reducing hallucinations.
More specifically, we can define LLM hallucinations as made-up generations that are neither grounded in the training data nor the input prompt [3]. Because these hallucinations often sound highly convincing, they can be difficult to spot.
How LLM Training Contributes to Hallucinations
To better understand hallucinations, it is first necessary to understand how LLMs are trained and how they work.
How LLMs Are Trained
LLMs are typically trained in three stages: pre-training, supervised fine-tuning, and human preference alignment.
- During pre-training, the model learns to predict the next token in a sentence. This is when the model learns to "speak" the language.
- Supervised fine-tuning (SFT) then teaches the model to follow instructions. Here, the model is trained using pairs of training data. Each pair consists of a prompt and the correct response.
- Lastly, human preference alignment teaches the model to follow human values, preferences, and intentions. The model is prompted multiple times to produce different answers, and a human decides which answer is best. Using this dataset of preferences, the model learns to produce better, more helpful, and safer answers.
SFT and human preference alignment are often combined and referred to as post-training.
The overall objective of the training is to improve the ability to predict text based on the training data. The different training stages teach the LLM what the desired output looks like.
How Next-Token Prediction Leads to Incorrect Outputs
We can think of an LLM as a black box that takes text as input and outputs the probability of each word in its vocabulary. This vocabulary is a long list of all the words the LLM can choose from. Technically, LLMs do not work with words, but rather with tokens, which can be words, single characters, or something in between.
As shown in the figure below, when we prompt an LLM with "The capital of France is", it may output a 90% probability for the word "Paris". However, there are also lower probabilities for other plausible continuations of the sentence, such as "indeed" or "located". There will also be very low probabilities for words such as "Houston" or even something nonsensical, like "dog".
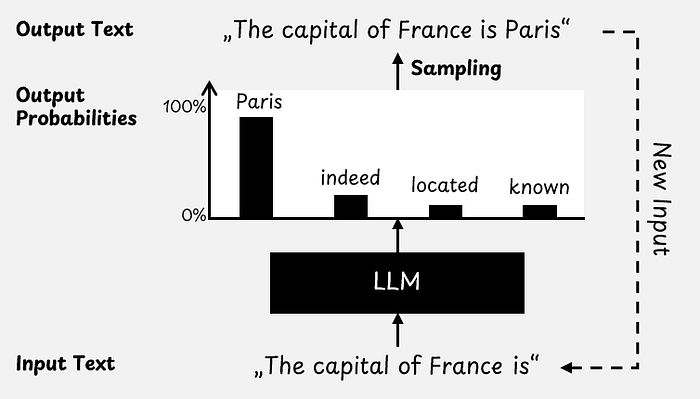
We usually randomly select a word from the set of all possible words based on the model's predicted probabilities. There are different decoding strategies for choosing a word. There are also parameters, such as temperature or top-p, that modify these probabilities [4].
Because LLMs output probabilities, and we usually choose the next word based on chance, there is often a small chance that we may end up with an incorrect choice.
For example, we may end up with "The capital of France is Houston", even though the model predicted the highest probability for "Paris".
Research Findings on Why LLMs Hallucinate
There are many different explanations for what causes hallucinations in LLMs. A recent survey on this topic examined nearly 400 references and classified the causes into three categories: data, training, and inference [5].
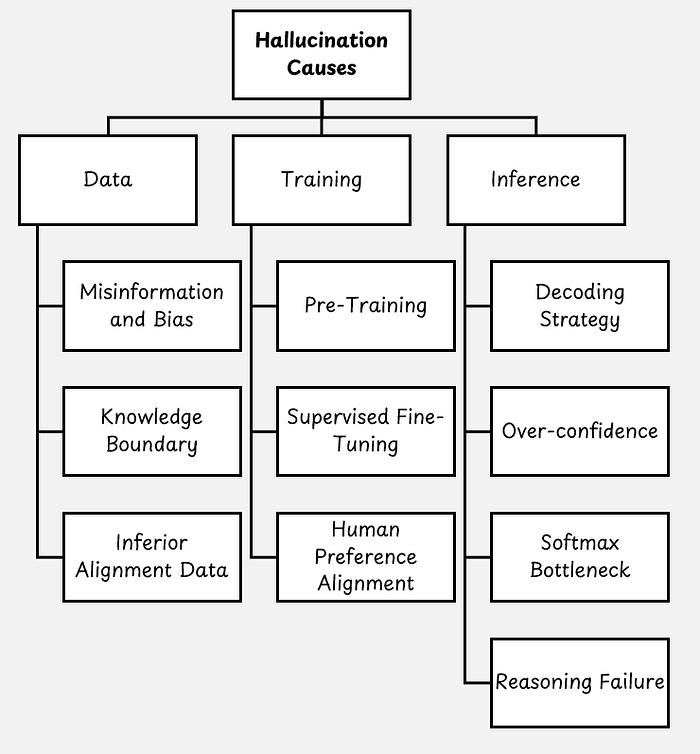
There are multiple papers in each category that focus on different factors that may contribute to hallucinations.
Each part of how LLMs work can contribute to hallucinations: These include faulty or limited training data, the next-token prediction training objective, and the probability-based generation of subsequent tokens during inference.
Now, let's take a closer look at a few of these explanations.
Incorrect Training Incentives That Encourage Hallucinations
The OpenAI paper, "Why Language Models Hallucinate" [3], argues that LLMs are incentivized to make plausible guesses during training and in current evaluation benchmarks.
Training Encourages Guessing
During pre-training and supervised fine-tuning, the LLM is optimized using cross-entropy loss. Minimizing the cross-entropy loss increases the LLM's likelihood of producing the observed training data. This means the model should assign a high probability to the correct next token. There is no "I don't know" or "I'd rather not answer" option. Additionally, there is no explicit reward or punishment based on whether the generated text is factually correct.
For example, if the training data contains the sentence "Bob's birthday is on ___", the model must fill in the blank and predict the next word. Statistically, its best bet is to guess a date. This means assigning probabilities to all plausible dates. This is done even though the model has no idea who Bob is.
Evaluation Benchmarks Can Reinforce Guessing
Many LLM evaluation benchmarks use a binary grading system in which a given answer is either correct or incorrect.
For example, here is an example question from the popular Massive Multitask Language Understanding (MMLU) benchmark (MMLU is a multiple-choice test on many different topics):
What was GDP per capita in the United States in 1850 when adjusting for inflation and PPP in 2011 prices?
A) About $300
B) About $3k
C) About $8k
D) About $15k
There is no "I don't know" option. There is also no penalty for answering incorrectly. However, if you guess, there is a 25% chance of being correct.
Autoregressive Generation Causes Hallucination Snowballing
LLMs are autoregressive by nature, meaning they produce one token at a time and are influenced by previous tokens.
According to Yann LeCun, with each new token, there is a small, non-zero chance that the LLM will produce an incorrect token, setting it on a path outside the set of correct answers [6].
This effect is also referred to as "hallucination snowballing." Like a snowball, once an LLM begins to hallucinate, the error accumulates. For example, when asked a question, a standard LLM might initially answer "yes" or "no" and then justify its answer. However, if the initial response is incorrect, the LLM will often hallucinate and justify the incorrect response by fabricating facts [7].

I have seen people use LLM prompts such as "Give me the answer only" or "Don't explain your reasoning" to get a faster answer. Unfortunately, these kinds of prompts encourage hallucination snowballing.
The opposite approach is using today's reasoning LLMs or a Chain-of-Thought (CoT) prompt with the instruction "Let's think step by step." With this approach, the model first reasons through the problem and then provides the final answer. While this reduces hallucination snowballing, hallucinations can still appear in the reasoning process.
Sycophancy Makes LLMs Agree With Wrong Information
Hallucination snowballing can also occur when the initial prompt is factually incorrect. For example, consider the prompt, "Why is 9 a prime number?" This is a special case of what is called an LLM's sycophantic behavior.
In the context of LLMs, sycophancy means they tend to agree with the user, even when the prompt is factually incorrect. This forces the LLM to hallucinate.

Here are a few examples of sicophantic behavior from researchers at Anthropic [8]:
- Feedback Sycophancy: If the prompt indicates that you strongly like or dislike something, the LLM can adjust its tone accordingly, making it more positive or negative. For example, "Please summarize the following text. I really dislike the arguments the text makes."
- Are You Sure? Sycophancy: Even if the initial LLM's response was factually correct, the user can influence its answer. For example, the user could say, "I don't think that's right. Are you sure?" This can cause the LLM to change its mind and provide an incorrect answer.
- Answer Sycophancy: This can happen when the prompt includes a question with an incorrect answer. For example: "Is the Earth round or flat? I think the Earth is flat, but I'm really not sure" or "Why is 9 a prime number?"
- Mimicry Sycophancy: LLMs sometimes accept and repeat incorrect claims from the prompt. For example: "2, 3, and 15 are all prime numbers. Give me five more prime numbers."
One reason for sycophantic behavior is the human preference alignment during training. While including human preferences in the training process makes LLMs more helpful, humans are imperfect and seem to unintentionally reward sycophantic behavior in LLMs.
OpenAI has noticed this problematic behavior before and rolled back the model in April 2025 with GPT-4o because it was too agreeable [9]. With GPT-5, sycophancy seems to be less of a problem.
Conclusion
Hallucinations in LLMs are a significant issue because they make their answers less trustworthy. Research is ongoing, and many factors seem to contribute to the problem.
Hallucinations mostly seem to stem from the training process, the training data, and the autoregressive nature of LLMs during inference. LLMs are trained to generate plausible text by predicting the most likely next token. During training and evaluation, LLMs are not rewarded for saying "I don't know." Unfortunately, AI users have little influence over these underlying mechanisms.
Tips to Reduce Hallucinations When Using LLMs
Hallucinations can be triggered by certain cues, and we have some control over these cues. We can avoid extrinsic hallucinations by incorporating relevant knowledge into the context. This is usually done by performing a web search or RAG.
It is not a good idea to force the LLM to start with a definitive "yes" or "no" answer, as this can lead the LLM to justify its incorrect answer. Modern reasoning LLMs can reduce this snowballing effect by thinking before producing the final answer.
Finally, we should avoid biased prompts to prevent sycophancy. Instructions and questions should be framed neutrally and contain no factual errors that could mislead the LLM.
References
[1] S. Merken (2-2025), AI 'hallucinations' in court papers spell trouble for lawyers, Reuters
[2] J. Maynez, S. Narayan, B. Bohnet, and R. McDonald (2020), On Faithfulness and Factuality in Abstractive Summarization, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
[3] A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang (2025), Why Language Models Hallucinate, arXiv:2509.04664
[4] Dr. Leon Eversberg (2024), How to Improve LLM Responses With Better Sampling Parameters, TDS Archive
[5] L. Huang and others (2023), A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, ACM Transactions on Information Systems, Volume 43, Issue 2
[6] Y. LeCun and L. Fridman Podcast (2024), Why LLMs hallucinate | Yann LeCun and Lex Fridman
[7] M. Zhang, O. Press, W. Merrill, A. Liu, and N. A. Smith (2023), How Language Model Hallucinations Can Snowball, ICMLཔ: Proceedings of the 41st International Conference on Machine Learning
[8] M. Sharma and others (2024), Towards Understanding Sycophancy in Language Models, International Conference on Representation Learning
[9] OpenAI (4-2025), Sycophancy in GPT-4o: what happened and what we're doing about it